Découverte de relations à l’aide de la régression linéaire
Objectifs de formation
Une fois cette unité terminée, vous pourrez :
- Donner la définition de la régression linéaire
- Distinguer les caractéristiques d’une corrélation et celles d’une régression linéaire
Présentation du concept de régression linéaire
Dans l’unité précédente, vous avez vu que la corrélation désigne la direction (positive ou négative) et la force (très forte à très faible) de la relation entre deux variables quantitatives.
À l’instar de la corrélation, la régression linéaire indique également la direction et la force de la relation entre deux variables numériques, mais elle utilise un ajustement affine pour prédire les valeurs Y à partir des valeurs X. Au sein d’une corrélation, les valeurs de X et Y sont interchangeables. Au sein d’une régression, les résultats de l’analyse changent si X et Y sont permutés.

La ligne de régression linéaire
Comme pour les corrélations, pour que les régressions soient significatives, vous devez :
- utiliser des variables quantitatives ;
- vérifier la présence d’une relation linéaire ;
- faire attention aux valeurs aberrantes.
Comme les corrélations, les régressions linéaires sont visualisées dans des nuages de points.
La droite de régression figurant sur le nuage de points est l’ajustement affine correspondant à l’ensemble des points du nuage. En d’autres termes, il s’agit d’une droite qui passe entre les points avec le moins de distance possible entre chaque point et la droite.
En quoi cette droite est-elle utile ? Eh bien, elle nous permet d’utiliser un calcul de régression linéaire pour calculer, ou prédire, une valeur Y si l’on dispose d’une valeur X connue.
Examinons un exemple pour que tout ceci soit plus clair.
Exemple de régression
Imaginons que vous souhaitiez connaître le budget nécessaire pour acheter une maison d’une superficie de 1 500 pieds carrés Utilisons la régression linéaire pour faire une prédiction.
- Placez la variable à prédire, à savoir le budget, sur l’axe des ordonnées (on l’appelle également la variable dépendante).
- Placez la variable sur laquelle vous faites reposer vos prédictions, la superficie en pieds carrés, sur l’axe des abscisses (on l’appelle également la variable indépendante).
Voici un nuage de points montrant le prix des maisons (axe des ordonnées) et la superficie en pieds carrés (axe des abscisses).

Ce nuage de points montre que les maisons avec une superficie plus importante ont tendance à avoir un prix plus élevé, mais combien devrez-vous dépenser pour une maison d’une superficie de 1 500 pieds carrés ?
Pour répondre à cette question, vous devez tracer une droite traversant ces points. C’est ce en quoi consiste la régression linéaire. La droite de régression vous permet de prédire le budget nécessaire pour un logement d’une certaine surface. Dans cet exemple, vous pouvez voir l’équation de la droite de régression.

L’équation de la droite est Y = 113*X + 98 653 (valeur arrondie).
Que signifie cette équation ? Elle indique que si vous effectuez un achat sans surface habitable (un terrain nu, par exemple), le prix sera de 98 653 $. Voici les étapes de résolution de l’équation.
Pour trouver Y, multipliez la valeur de X par 113, puis ajoutez 98 653. Dans le cas présent, nous nous intéressons à une superficie de zéro pied carré, donc la valeur de X est 0.
- Y = (113 * 0) + 98 653
- Y = 0 + 98 653
- Y = 98 653
La valeur 98 653 est appelée ordonnée à l’origine, car elle représente le point d’intersection entre la droite et l’axe des ordonnées. Elle correspond à la valeur de Y lorsque X est égal à 0.
Le nombre 113 représente la pente (coefficient directeur) de la droite. La pente est un nombre qui indique à la fois la direction et l’inclinaison de la droite. Dans le cas présent, la pente indique que pour chaque pied carré de superficie, le prix augmente de 113 $.
Voici donc ce que vous devez dépenser pour une maison d’une superficie de 1 500 pieds carrés :
Y = (113 * 1500) + 98 653 = 268 153 $
Observez à nouveau ce nuage de points. Les repères bleus représentent les données. Vous pouvez voir que vous avez des données concernant des maisons d’une superficie comprise entre 1 100 et 2 450 pieds carrés.
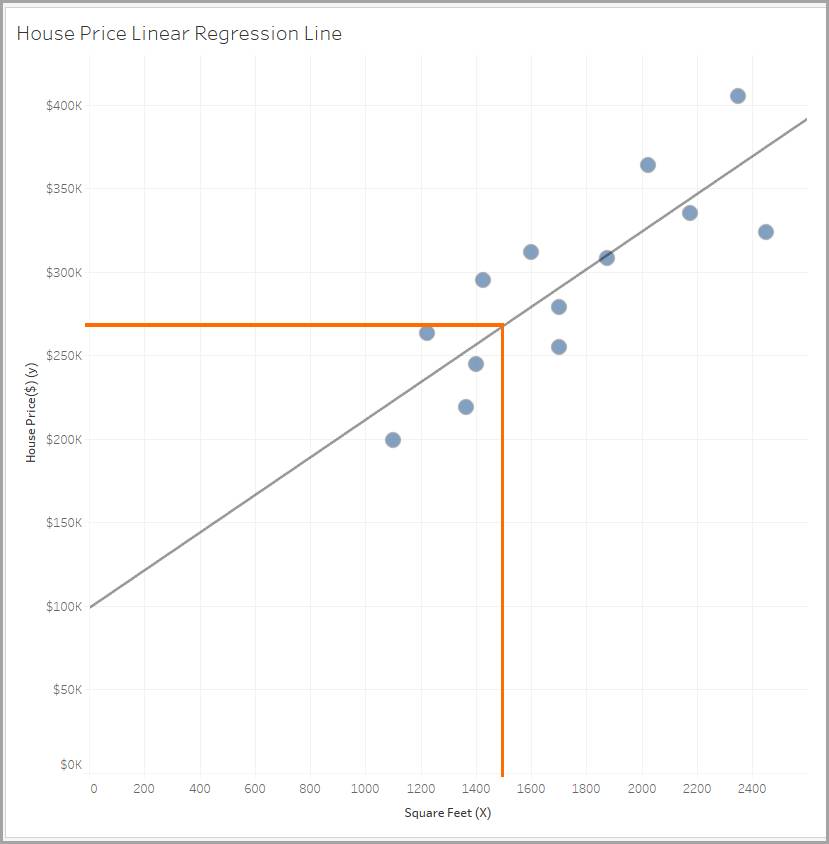
Notez que cette équation ne peut pas être utilisée pour prédire le prix de toutes les maisons. Étant donné qu’une maison de 5 000 pieds carrés et une maison de 10 000 pieds carrés sont toutes deux en dehors de la plage des données réelles, vous devez faire preuve de prudence lorsque vous faites des prédictions avec ces valeurs en utilisant cette équation.
La valeur r²
En plus de l’équation dans cet exemple, nous constatons également la présence d’une valeur r² (également appelée coefficient de détermination).

Cette valeur est une mesure statistique de la proximité des données par rapport à la droite de régression, ou de l’adéquation du modèle à vos observations. Si les données se trouvent parfaitement sur la droite, la valeur r² serait égale à 1, ou 100 %, ce qui signifie que votre modèle est parfaitement adéquat (tous les points de données observés se trouvent sur la droite).
Pour nos données sur le prix des maisons, la valeur r² est égale à 0,70, soit 70 %.
Comparaison entre la régression linéaire et la corrélation
Maintenant, vous vous demandez peut-être comment distinguer la régression linéaire de la corrélation. Reportez-vous au tableau ci-dessous pour voir un résumé de chaque concept.
Régression linéaire |
Corrélation |
|---|---|
Affiche un modèle linéaire et une prédiction, prédisant Y à partir de X. |
Affiche une relation linéaire entre deux valeurs. |
Utilise r² pour mesurer le pourcentage de variation expliqué par le modèle. |
Utilise r pour mesurer la force et la direction de la corrélation. |
N’utilise pas X et Y comme valeurs interchangeables (car Y est prédit à partir de X). |
Utilise X et Y comme valeurs interchangeables. |
En connaissant bien les concepts statistiques de corrélation et de régression, vous serez mieux à même d’explorer et de comprendre les données avec lesquelles vous travaillez en examinant les relations.
Ressources