Découverte des fondamentaux des bases de données
Objectifs de formation
Une fois cette unité terminée, vous pourrez :
- Identifier cinq étapes marquantes dans l’histoire des bases de données
- Différencier les bases de données relationnelles de celles non relationnelles
- Définir la notion de « Big Data »
Histoire des bases de données
La phrase « c’est hébergé dans le Cloud » nous est maintenant bien familière. En l’entendant, on l’imagine comme quelque chose d’intangible, semblable à de la vapeur ou à de la brume. Bien sûr, la réalité est tout autre : le Cloud correspond simplement à des centres de données physiques remplis de serveurs. Salesforce en possède un grand nombre dans le monde entier. Mais comment toutes ces données sont-elles organisées ? Comment y accède-t-on ? Tout dépend du type de base de données. Cette unité représente un cours intensif sur les concepts clés des bases de données.
Calendrier
L’histoire des bases de données commence dans les années 60, quand les ordinateurs faisaient la taille d’une pièce.

Décennie |
Jalons |
|---|---|
Années 60 |
Le terme « base de données » est apparu au début des années 60, lorsque les disques ont remplacé le stockage sur bande. Les premières bases de données étaient non relationnelles, c’est-à-dire qu’il s’agissait simplement de listes chaînées d’enregistrements sous forme libre. Les choses ont évolué dans la décennie suivante. |
Années 70 |
Les années 70 ont vu le lancement des bases de données relationnelles, qui ont fini par devenir la norme. Contrairement aux bases de données précédentes, celles-ci donnaient accès à des tables normalisées, liées et interrogeables. |
Années 80 |
L’informatique de bureau s’est largement démocratisée dans les années 80, tout comme les logiciels d’entreprise conviviaux interagissant avec des bases de données sous-jacentes. |
Années 90 |
Dans les années 90, la programmation orientée objet (OOP) a rendu possible l’organisation des données par classe et attribut plutôt que par tableau et par champ, qui était plus sommaire. |
Années 2000 |
Les bases de données non relationnelles ont fait leur retour dans les années 2000 sous la forme de bases de données NoSQL (pas seulement SQL). Simples et très évolutives, elles répondent aux exigences du Big Data et des applications Web en temps réel. |
Maintenant que nous en savons un peu plus sur l’histoire des bases de données, intéressons-nous de plus près à deux des grandes manières de les classer.
Relationnelle ou non relationnelle
Les bases de données relationnelles sont les plus usitées depuis des décennies et répondent toujours aux besoins actuels. Elles répartissent les données au sein de plusieurs tables liées. Les tables parent contiennent des lignes où figurent des identifiants uniques appelés « clés primaires ». Les tables enfant référencent ces clés primaires à l’aide d’autres identifiants (les « clés étrangères »). Dans le diagramme ci-dessous, la table A est le parent et la table B est l’enfant.
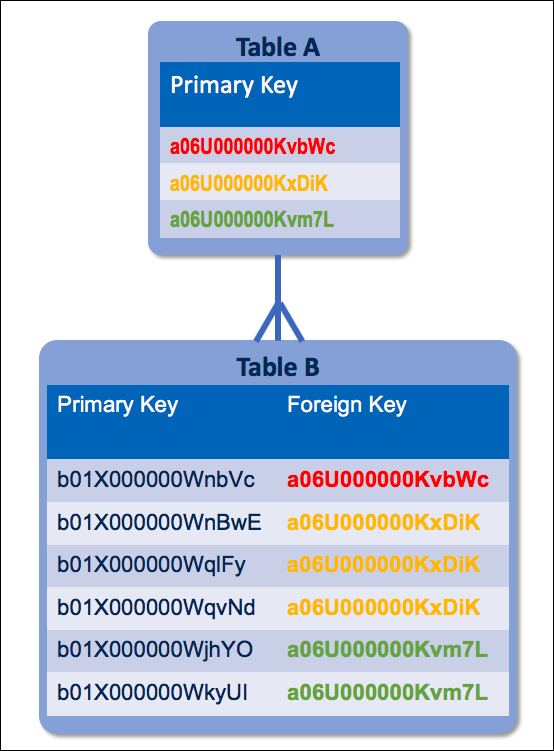
Caractéristiques des bases de données relationnelles
En règle générale, les administrateurs et les développeurs accèdent aux données d’une base de données relationnelle et les manipulent à l’aide du langage SQL (Structured Query Language). Les transactions présentent quatre caractéristiques dont vous pouvez vous rappeler à l’aide de l’acronyme « ACID ». Les bases de données relationnelles accordent plus d’importance à la cohérence qu’à la disponibilité.
- Atomique : toutes les tâches doivent s’effectuer correctement ou la transaction est annulée.
- Cohérence : l’état de la base de données doit rester cohérent tout au long de la transaction.
- Isolation : chaque transaction est distincte et ne dépend pas des autres.
- Durabilité : il est possible de récupérer les données d’une transaction ayant échoué.
Les bases de données relationnelles sont parfaites pour effectuer des opérations sur des données complexes, ainsi que pour les analyser. Elles suivent une structure stricte dans laquelle les données doivent trouver leur place.
Toutefois, dans certains cas, il n’est pas possible de classer des données au sein d’une structure bien définie. Cela a commencé à se produire lors de l’essor d’Internet dans les années 90 : les applications Web se sont mises à générer des données n’appartenant pas à une catégorie spécifique. Nous avons assisté à un retour en force des bases de données non relationnelles, que nous appelons parfois bases de données « NoSQL » ou « pas seulement SQL » aujourd’hui.
Types de bases de données non relationnelles

Il existe quatre types de bases de données non relationnelles :
- Les paires clé-valeur utilisent le modèle dit du « tableau associatif », ce qui signifie que les données figurent dans un ensemble de paires (clé + valeur).
- Les magasins orientés colonne arborent une structure en tableaux. Les colonnes des tableaux peuvent varier de ligne en ligne.
- Les systèmes orientés document enregistrent les informations relatives à chaque document sous la forme d’une instance unique dans la base de données. Les documents peuvent être imbriqués.
- Les graphiques structurent des éléments ainsi que les relations entre ces derniers. Ils coordonnent également les attributs attribués à la fois aux éléments et aux relations.
Caractéristiques des bases de données non relationnelles
Les bases de données non relationnelles partagent toutes trois caractéristiques importantes (vous pouvez vous en souvenir à l’aide de l’acronyme DÉCO). Elles accordent plus d’importance à la disponibilité qu’à la cohérence, ce qui est le contraire des bases de données relationnelles.
- Disponibilité totale : le système est toujours disponible, même en cas de panne.
- États non-définitifs : l’état des données peut être sujet à des modifications.
- Cohérence ultérieure : la cohérence n’est pas garantie lors des transactions, mais les données finissent par être synchronisées via l’ensemble des nœuds.
Leur structure étant facile à modéliser, les bases de données non relationnelles sont hautement évolutives. Toutefois, elles peuvent présenter des lacunes en matière de cohérence, car elles n’offrent pas la garantie que tous les clients ont accès aux mêmes données en même temps.
Une comparaison s’impose.
Base relationnelle |
Base non relationnelle |
|---|---|
Normalisée |
Dénormalisée |
SQL |
SQL limité ou SQL asynchrone |
Données structurées |
Données structurées ou non structurées |
Transactions ACID |
Peu ou pas de transactions |
Il n’existe pas de type de base de données meilleur que l’autre : chacun d’entre eux répond à des besoins professionnels différents. Par exemple, pour traiter de très grands volumes d’informations, les bases non relationnelles sont les plus adaptées.
Découverte du Big Data
À l’évocation du « Big Data », on s’imagine quelque chose d’impressionnant. Mais de quoi s’agit-il réellement ? Le Big Data fait référence à tout ensemble de données trop volumineux ou complexe pour être traité par un logiciel d’application traditionnel. Nous parlons ici d’ensembles composés de centaines de millions (voire de milliards) de lignes. Maintenant que le stockage est bon marché et que le traitement est rapide, le Big Data est omniprésent. En effet, l’intelligence artificielle (IA) tire parti de l’apprentissage machine pour traiter les enregistrements plus rapidement que n’importe quel humain.
Compte tenu de ces coûts bas et de cette rapidité de traitement, les entreprises ne veulent désormais plus supprimer aucune donnée. Mais comment peuvent-elles déterminer si elles doivent opter pour des bases de données non relationnelles, qui leur permettraient de gérer l’énorme quantité de données variées, ou bien relationnelles, qui leur permettraient de gérer une logique métier complexe ? En réalité, elles ont besoin d’une architecture d’entreprise qui réalise tout cela. Plusieurs technologies différentes peuvent être incluses dans une solution complète.
Maintenant que vous en savez davantage sur les bases de données et sur les défis posés par le Big Data, nous vous expliquerons dans l’unité suivante comment utiliser Salesforce pour stocker des données.