Explorar la granularidad
Objetivos de aprendizaje
Después de completar esta unidad, podrá:
- Definir qué es la granularidad.
- Identificar cómo la agregación y la granularidad inciden en los datos.
¿Qué es la granularidad?
La granularidad hace referencia al nivel de detalle de los datos. En la unidad anterior, vimos el siguiente gráfico de barras con todos los valores de la variable Age (Edad) agregados como una suma. La información no es muy detallada, por lo que el nivel de granularidad es bajo.
El gráfico de barras muestra datos agregados, con un solo número para todo el conjunto de datos. El gráfico de nube muestra datos desagregados, con una marca para cada valor. El gráfico de nube es más detallado, por lo que tiene una granularidad mayor que el gráfico de barras. El gráfico de barras es de alta agregación y baja granularidad. El gráfico de nube es de baja agregación y alta granularidad.
|
|
|---|
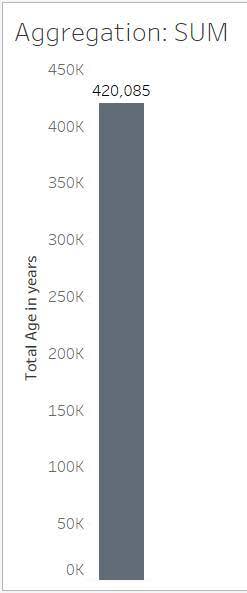
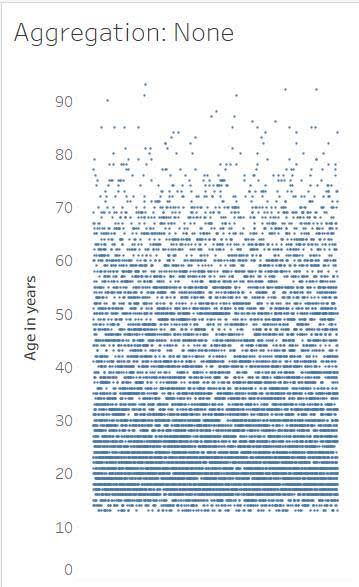
Estos datos desagregados muestran el nivel de detalle más bajo, que proporciona la granularidad más baja de todas las visualizaciones. El nivel de detalle más bajo es una de las características de los datos significativos, tal como se explica en el módulo Datos bien estructurados.
Ejemplos de granularidad
Vamos a seguir explorando la granularidad. Utilizaremos un conjunto de datos con información sobre una franquicia y examinaremos los datos con niveles de granularidad.
Este conjunto de datos contiene más de 50 000 filas. Cada una de las filas contiene información sobre una sola transacción. Con una granularidad menor (mayor agregación), es posible ver patrones más amplios. Si aumentamos la granularidad (menor agregación), podemos ver los detalles detrás de los patrones.
Un gráfico de dispersión es un gráfico que permite a los usuarios representar datos numéricos (variables cuantitativas) tanto en el eje horizontal como en el vertical para identificar correlaciones o relaciones entre valores. En este ejemplo, utilizamos un gráfico de dispersión a fin de explorar la relación entre las ventas y las ganancias de una empresa.
Visualizar un gráfico de dispersión con dos variables cuantitativas
Comenzamos con las variables cuantitativas Profit (Ganancias) y Sales (Ventas), que se muestran en el siguiente gráfico de dispersión.
Aquí, un número (Ventas) se representa en función de otro (Ganancias). Los dos números se comparan con un solo punto de datos o marca porque las ventas y las ganancias se agregan completamente a un solo número (suma de ventas y suma de ganancias).
La información no es muy detallada, por lo que el nivel de granularidad es bajo. Para saber más sobre las ganancias y las ventas de la empresa, los datos deben presentar más granularidad.

Visualizar un gráfico de dispersión con una variable cualitativa agregada
Cuando se agrega una variable cualitativa al gráfico de dispersión, aumenta la granularidad de los datos.
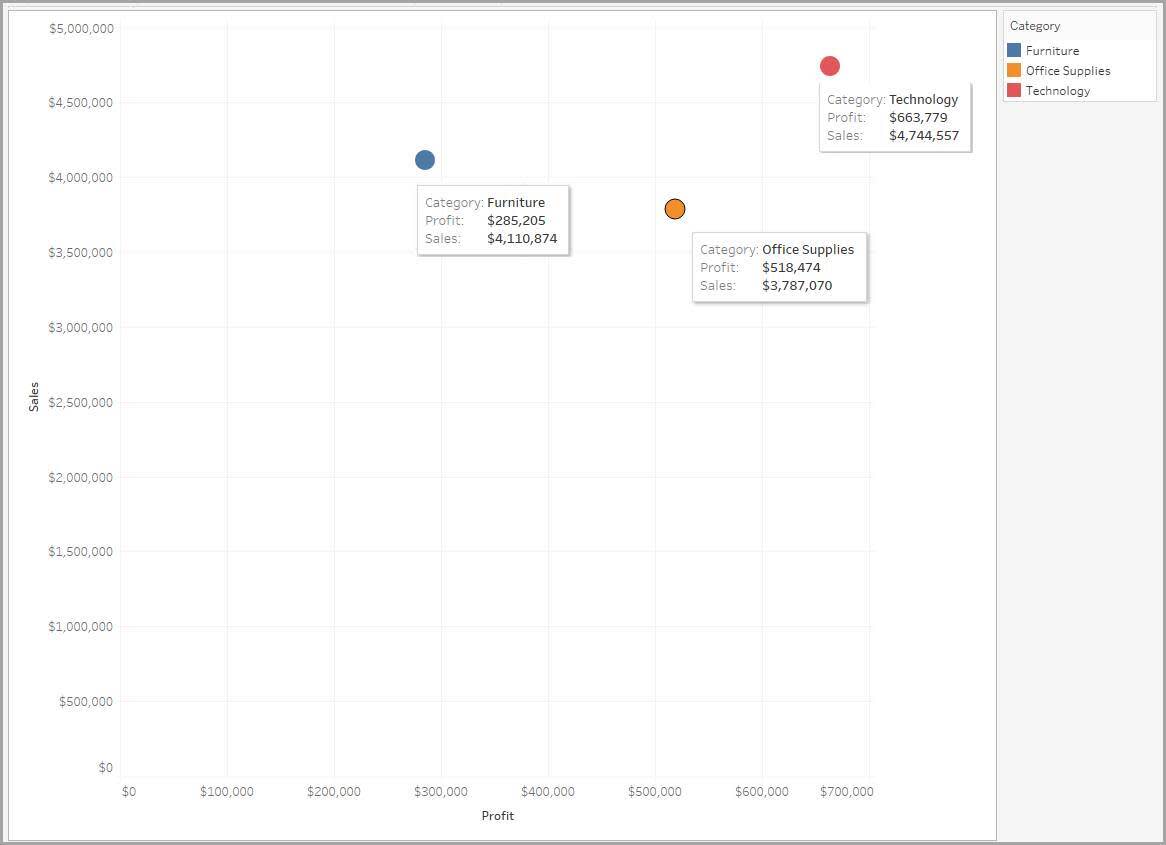
Con la variable cualitativa Category (Categoría) codificada por color, los datos ahora se dividen en tres marcas, una para cada categoría de producto a la venta. Hay más granularidad que en el gráfico de dispersión de una marca, pero aún puede ver los datos con más detalle.
Observe las ganancias por categoría en el siguiente gráfico de dispersión. Las ganancias relativas al mobiliario están por debajo de las otras dos. A continuación, se recomienda aumentar la granularidad investigando si esta tendencia se mantiene en todos los mercados geográficos.
Visualizar un gráfico de dispersión con una segunda variable cualitativa agregada
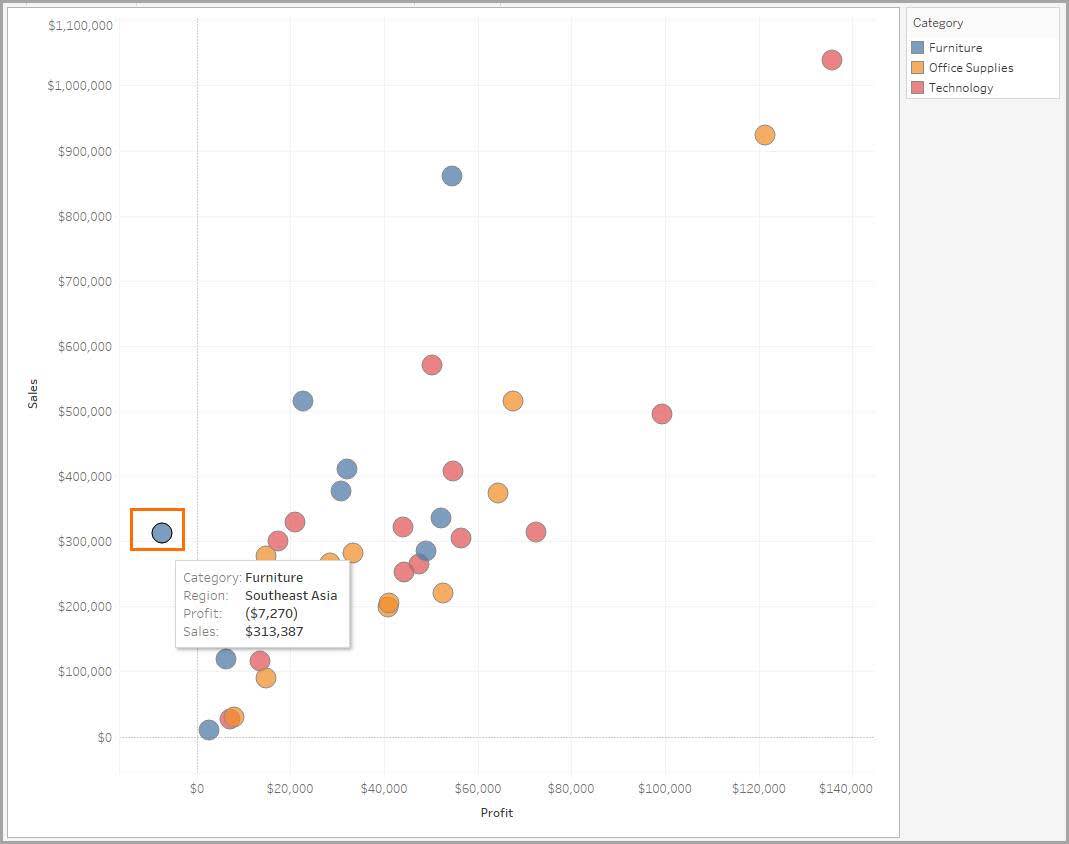
Con la variable cualitativa Region (Región) que se agrega a la siguiente visualización, puede explorar si las ganancias referentes al mobiliario son más bajas en todos los mercados geográficos. El número de regiones discretas de la fuente de datos se multiplica por el número de categorías para crear marcas en el gráfico de dispersión. Por lo tanto, las 13 regiones se multiplican por las 3 categorías y, como resultado, se crean 39 marcas en el gráfico de dispersión.
Ahora los datos tienen la suficiente granularidad para poder ver una posible causa de las ganancias bajas referentes al mobiliario. La región del Sudeste Asiático tiene ganancias en mobiliario notablemente más bajas que otras regiones. Puede seguir aumentando la granularidad de los datos para profundizar en los valores negativos de ganancias en cuanto al mobiliario en esa región.
Visualizar un gráfico de dispersión con datos filtrados
Observa que la región del Sudeste Asiático tiene ganancias en cuanto al mobiliario notablemente más bajas que otras regiones. Tendrá que ver si esta falta de rentabilidad se debe a una o dos transacciones, o sin son muchas las transacciones poco rentables.
Sabe que el conjunto de datos incluye una fila para cada transacción. Si los datos están desagregados, solo verá un punto de datos (o marca) por cada transacción en el conjunto de datos. Antes de desagregar los datos a este nivel, fíltrelos para conservar solo las transacciones sobre mobiliario en la región del Sudeste Asiático.
El siguiente gráfico de dispersión muestra los datos filtrados que contienen solo una marca para mobiliario en el Sudeste Asiático.


Visualizar datos desagregados
Con los datos filtrados para mostrar solo el mobiliario del Sudeste Asiático, ahora puede ver la máxima granularidad de datos.
Al desagregar los datos, se muestra una marca independiente para cada valor de datos en cada fila de los datos seleccionados. En la siguiente visualización, se observa una marca por cada transacción de mobiliario en el Sudeste Asiático. Explorar los niveles de granularidad de esta manera permite conseguir un hallazgo importante: muchas transacciones de venta de muebles no son rentables en el Sudeste Asiático.

Ahora ya sabe el impacto que provocan las agregaciones predefinidas en los datos y cómo afectan los diferentes niveles de granularidad al análisis de datos.
Recursos
-
Ayuda de Tableau: Scatterplots, Aggregation, and Granularity (Gráficos de dispersión, agregación y granularidad)
-
Sitio de Tableau: Free Training Videos (Vídeos de formación gratuitos)
-
Sitio externo: Tableau Tutorials: How to Build a Jitter Plot