Usar la API masiva 2.0
Objetivos de aprendizaje
Después de completar esta unidad, podrá:
- Describir las diferencias entre una solicitud asíncrona y una solicitud síncrona.
- Crear un trabajo masivo con la aplicación web Postman.
- Importar datos en su organización de Salesforce mediante la adición de datos a un trabajo.
- Monitorear el progreso de un trabajo.
- Obtener los resultados de un trabajo.

API masiva y solicitudes asíncronas
La API masiva se basa en los principios de REST y se ha optimizado para trabajar con grandes conjuntos de datos. Puede usarla para insertar, actualizar, insertar y actualizar o eliminar muchos registros de forma asíncrona, lo que significa que puede enviar una solicitud y consultar los resultados posteriormente. Salesforce procesa la solicitud en segundo plano.
Por el contrario, la API de SOAP y la API de REST usan solicitudes síncronas y se han optimizado para aplicaciones cliente en tiempo real que actualizan unos cuantos registros a la vez. Estas dos API se pueden usar para procesar muchos registros, pero cuando los conjuntos de datos contienen cientos de miles de registros, dichas API son menos prácticas. El marco asíncrono de la API masiva se ha diseñado para garantizar el procesamiento de los datos de forma sencilla y eficiente con independencia de que se trate de unos cuantos miles o millones de registros.
La forma más sencilla de usar la API masiva es activarla para el procesamiento de registros en el Cargador de datos mediante archivos CSV. El uso del Cargador de datos elimina la necesidad de escribir su propia aplicación cliente. No obstante, en el caso de determinados requisitos únicos, puede ser necesario desarrollar una aplicación personalizada. La API masiva le permite hacerse con el timón del barco y dirigir el rumbo para encontrar la mejor solución en su caso.
Para esta unidad utilizará una versión más reciente de la API masiva denominada API masiva 2.0. Si desea aplicar las cosas que aprenda en esta unidad en la versión anterior de la API masiva, que aún es compatible, tendrá que utilizar URI de recursos diferentes, y crear y gestionar lotes así como trabajos. Para obtener más información acerca de la versión anterior de la API masiva, consulte Guía del desarrollador de API masiva.
Configurar Playground y Postman
Para explorar la API masiva, vamos a utilizar Postman para crear algunos registros de cuenta.
- Inicie sesión en su Trailhead Playground.
- Inicie sesión en la aplicación web Postman.
- Obtenga un token nuevo y conecte Playground a Postman.
- Pruebe que su conexión funcione con el recurso Límites mediante GET de REST.
Aprendió cómo hacer esto en Inicio rápido: Conectar Postman a Salesforce, así que vuelva a revisar ese proyecto si tiene dudas sobre alguno de los pasos.
Crear un trabajo masivo
El primer paso es crear un trabajo en su bifurcación de la recopilación de API de Salesforce. Un trabajo especifica el tipo de operación y objeto de datos con los que trabaja. Funciona como un depósito al que agrega datos para el procesamiento.
- En Recopilaciones, abra la carpeta Bulk v2.
- Haga clic en POST Create job (Crear trabajo mediante POST).

Dado que la API masiva se basa en REST, la solicitud adopta la forma ya familiar de una solicitud REST con cuatro componentes: URI, método HTTP, encabezados y cuerpo. El método HTTP es POST.
Observe el URI integrado en la ventana principal cuando hace clic en el recurso en la recopilación: /services/data/v{{version}}/jobs/ingest. Revisemos algunos detalles relacionados con este URI.
- Utilizamos /services/data, que es el mismo extremo que se utiliza para la API de REST. La API masiva utiliza el mismo marco de trabajo que la API de REST, lo que significa que la API masiva admite muchas de las mismas funciones, como la autenticación de OAuth.
-
/jobs/ingestindica que accede al recurso para crear los trabajos de API masiva.

Cree el cuerpo de la solicitud.
Para crear un trabajo de API masiva 2.0, use el campo de solicitud lineEnding si quiere especificar el final de línea utilizado para crear el texto con formato CSV. API masiva 2.0 admite dos formatos de fin de línea: salto de línea (LF) y retorno de carro más salto de línea (CRLF). El valor predeterminado lineEnding, si no se especifica, es LF. Diferentes sistemas operativos utilizan distintos caracteres para marcar el fin de una línea:
- Unix/Linux/OS X usan LF (salto de línea, '\n', 0x0A).
- Windows/DOS usan CRLF (retorno de carro seguido de salto de línea, '\r\n', 0x0D0A).
Tenga en cuenta que los editores de texto que se utilizan para crear un archivo CSV pueden estar configurados para un formato específico de fin de línea que sustituye el formato predeterminado del sistema operativo.
- Copie el cuerpo del CSV de ejemplo de su navegador y péguelo en un editor de texto para eliminar el formato. Indique el fin de línea correcto con el campo de solicitud
lineEndingsegún el sistema operativo y el editor de texto que esté utilizando. En el ejemplo, usamos un equipo Windows con "CRLF" como valor del parámetrolineEnding.
{
"operation" : "insert",
"object" : "Account",
"contentType" : "CSV",
"lineEnding" : "CRLF"
}- Copie el cuerpo en CSV de muestra del editor de texto y péguelo en la ficha Body (Cuerpo) en Postman.
- Haga clic en Save (Guardar).
- Haga clic en Enviar y compruebe la respuesta.
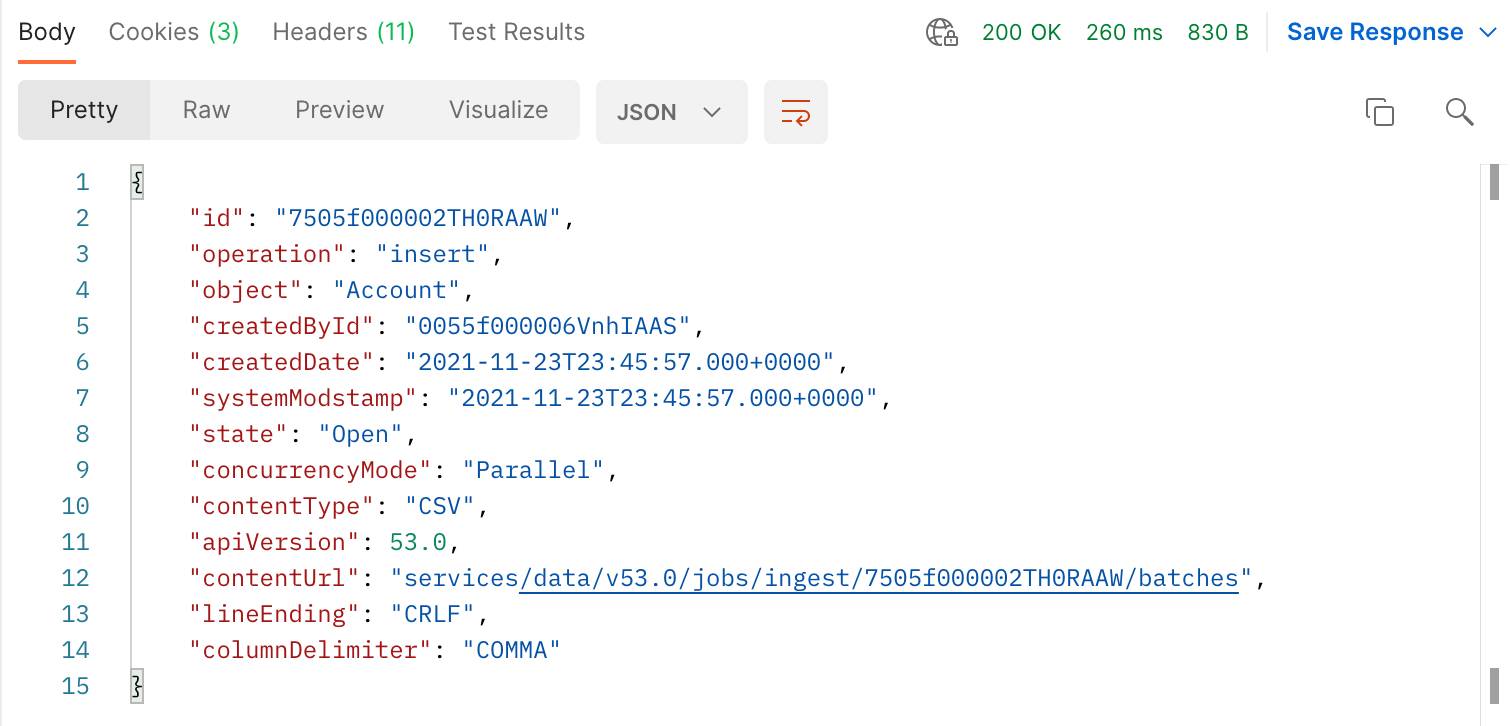
La respuesta incluye todo tipo de propiedades acerca del trabajo, la mayoría no son útiles en el momento porque no se agregaron datos todavía. Sin embargo, echemos un vistazo a algunas cosas.
- Observe la fila
"id". Esto muestra el Id. de trabajo devuelto para este trabajo.
- Haga clic en la ficha Scripts (Secuencias de comandos) para ver una secuencia de comandos que usa la variable __jobId y, así, establecer el contexto. Esta secuencia de comandos automáticamente agrega la Id. de trabajo a la variable __jobId. Esto inyecta la Id. de trabajo en futuras solicitudes para que no tenga que copiarla y pegarla.
- Puede ver el valor de __jobId en la ficha Variables de la recopilación.
- Luego, observe la propiedad
"state"(estado).
- Cuando crea un trabajo, el estado se establece de inmediato en Open. Esto significa que está listo para empezar a recibir datos.
- Por último, observe la propiedad
"contentUrl".
- Esta propiedad muestra la URL que utiliza para cargar datos para el trabajo.
Agregar datos al trabajo
Ahora podemos insertar datos de cuenta en nuestro trabajo. Los datos para un trabajo se envían al servidor como un conjunto de registros en una solicitud PUT. El servidor procesa el conjunto de registros, determinando la manera óptima de cargar datos en Salesforce. Todo lo que tiene que hacer es cargar los datos.
Cree una nueva solicitud en Postman. En la bifurcación de la recopilación de las API de Salesforce, en la carpeta Bulk v2, haga clic en Cargar datos de trabajo mediante PUT. Observe que el método HTTP es PUT.
Para este ejemplo, agrega un conjunto de registros con solo cuatro cuentas. Normalmente, la API masiva se usa para agregar miles o millones de registros, pero el principio es el mismo. Puede cargar un archivo CSV si selecciona el botón de opción binario y carga el archivo .csv, o bien puede pegarlo en una lista. En este ejemplo, se pega en una lista.
- Haga clic en la ficha Cuerpo y seleccione Sin procesar en el menú desplegable.
- Copie el siguiente texto en un editor de texto para aclarar cualquier formato adicional, luego, cópielo del archivo de texto al campo de cuerpo de la solicitud.
"Name" "Global Treasures & Mapping Company" "Ahab’s Mighty Masts" "Planks R Us" "Cap’n Cook’s Kitchen Supplies"

- Haga clic en Headers (Encabezados). Observe que Tipo de contenido dice
text/csv.Eso es debido a que especificó el tipo de contenido en su primera solicitud.

- Haga clic en Save (Guardar).
- Haga clic en Enviar.
La respuesta contiene solo un código de estado de 201 creado, que indica que Salesforce recibió correctamente los datos de trabajo.

Cerrar el trabajo
Ahora que envió los datos, necesita comunicar a Salesforce que es el momento de procesar esos datos.
- En la bifurcación de API de Salesforce, Bulk v2, la carpeta de consulta, haga clic en Cerrar o anular un trabajo mediante PATCH.
- Haga clic en la ficha Body (Cuerpo) y observe que
"state"(estado) ya se rellenó con “UploadComplete”.
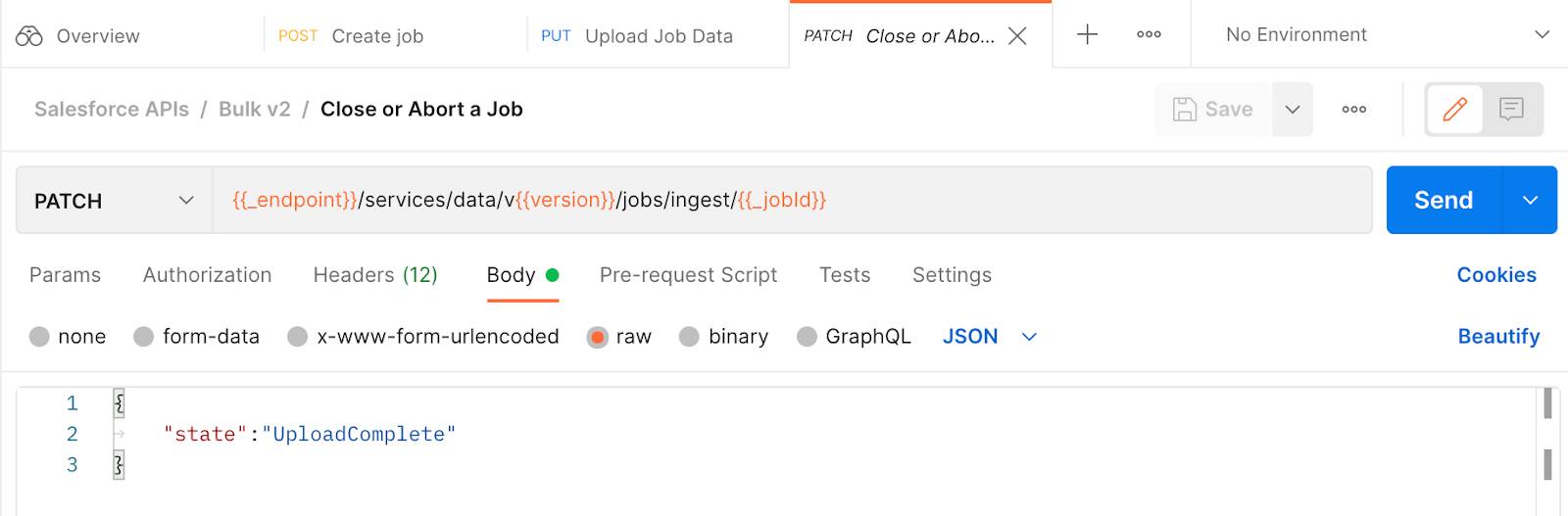
- Haga clic en la ficha Encabezados y observe que el tipo de contenido se estableció en
application/json.

- Haga clic en Enviar.
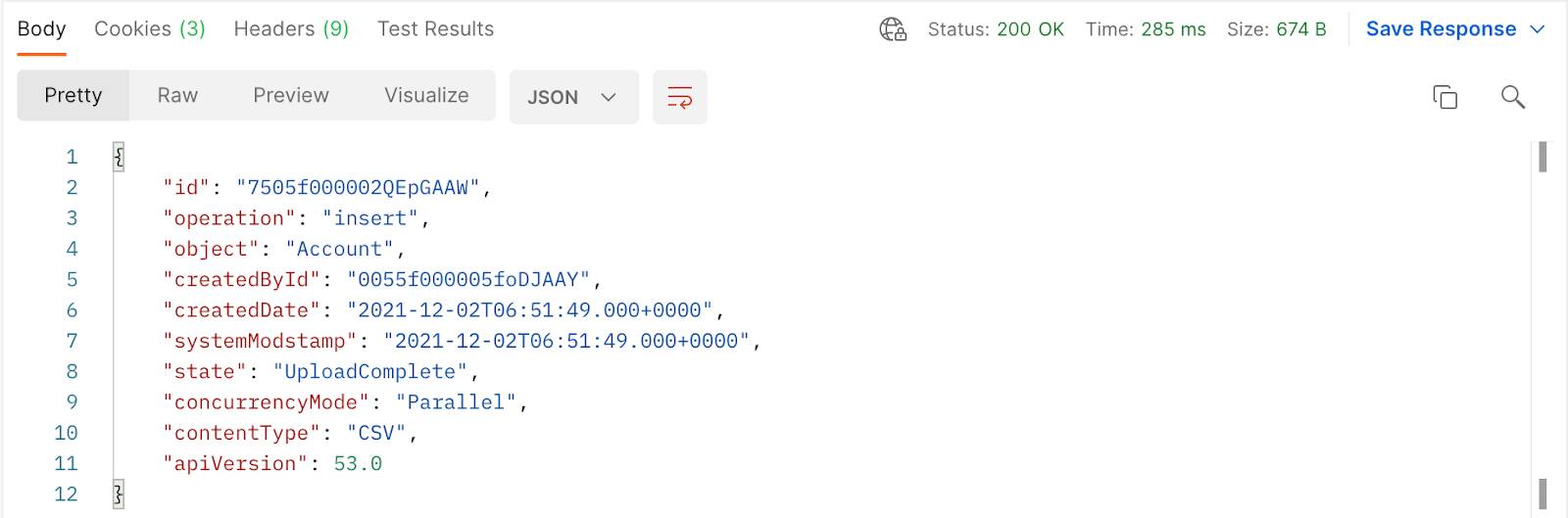
La respuesta contiene información sobre el estado del trabajo. La propiedad de estado indica que el estado del trabajo es UploadComplete. En este punto, Salesforce empieza a procesar el trabajo.
Comprobar el estado del trabajo
Ya envió los datos e informó a Salesforce que terminó de cargarlos. A continuación, el servidor debe procesar la solicitud. Puede supervisar el progreso del servidor mediante la comprobación del estado del trabajo en la interfaz de usuario de Salesforce o la API. Echemos un vistazo a cada método.
A continuación le mostramos cómo comprobar el estado del trabajo en su Trailhead Playground.
- En Setup (Configuración), ingrese
Bulk Data Load Jobs(Trabajos de carga de datos masivos) en el cuadro Búsqueda rápida
- Seleccione Trabajos de carga de datos masivos.
Puede comprobar el estado de un trabajo en esta página. O bien, puede hacer clic en un Id. de trabajo para comprobar el estado y obtener resultados para dicho trabajo.

A continuación le mostramos cómo comprobar el estado del trabajo en Postman desde la carpeta Bulk v2.
- Seleccione Información de trabajo mediante GET. Observe que el método http utilizado para este tipo de solicitud es GET.
- Haga clic en Enviar.
Verá algo como esto.
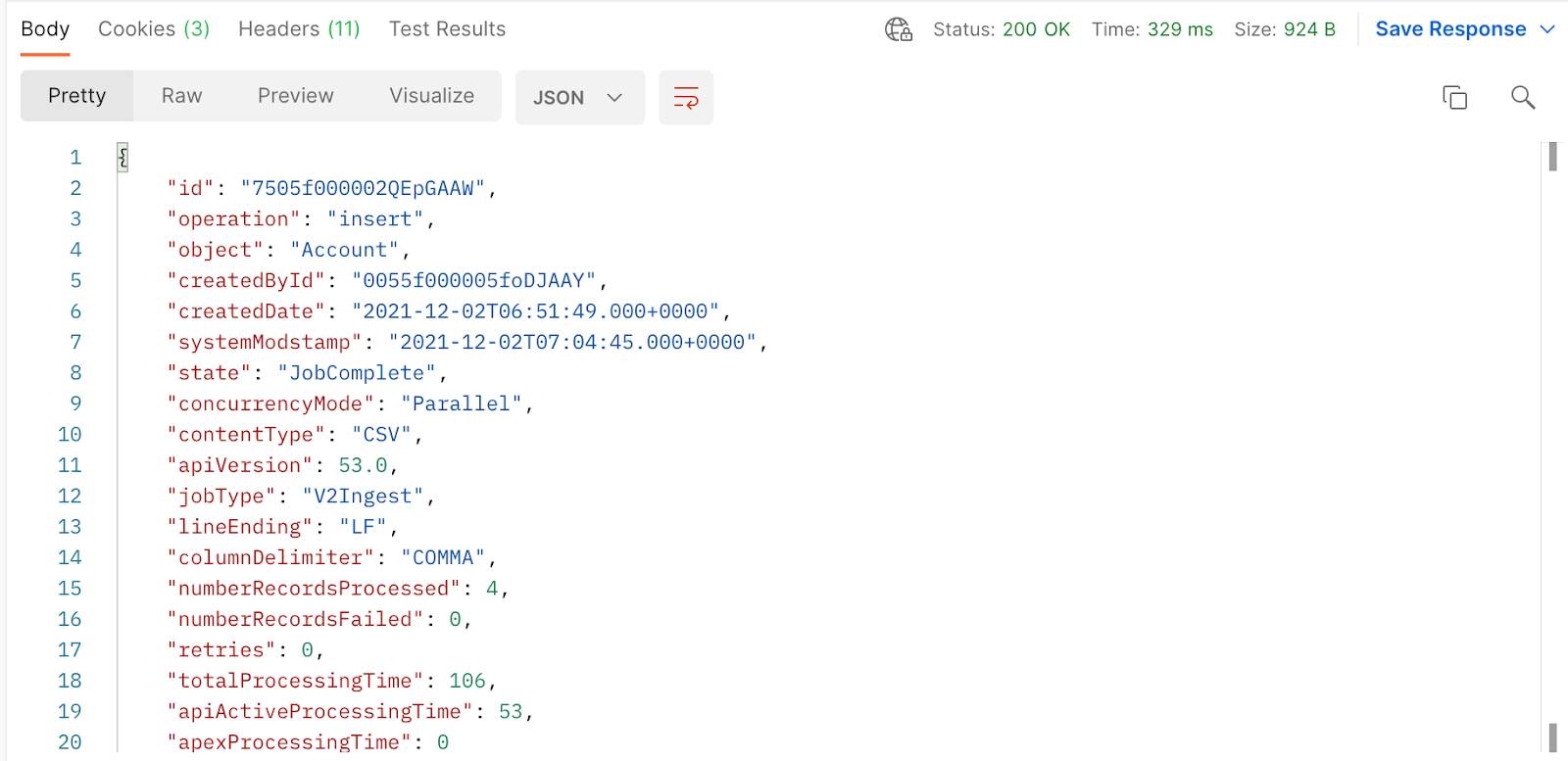
Si su estado aún es UploadComplete en vez de JobComplete, Salesforce aún está procesando el trabajo. No se preocupe, se procesará en unos minutos. Mientras tanto, tómese un momento para descansar y, luego, pruebe nuevamente con la misma solicitud. Si tiene suerte y su trabajo ya se procesó, podrá recuperar los resultados del trabajo.
Obtener los resultados del trabajo
Una vez que el trabajo está en estado JobComplete (o Failed) puede obtener información sobre los resultados en forma de registros procesados correcta e incorrectamente.
Echemos un vistazo primero a los registros procesados correctamente en la carpeta Bulk v2.
- Haga clic en el recurso GET Obtener resultados de registros de trabajo correctos. Observe que el método HTTP es GET.
- Haga clic en Enviar. Verá algo como esto.

Salesforce devuelve una lista de todos los registros del trabajo que se procesaron correctamente. En este módulo, creó varios registros Cuenta. La línea 1 muestra los tipos de valores de las respuestas devueltas debajo. Los datos de lista contienen los Id. de registros creados, un valor de verdadero para las columnas sf__Created y los nombres de las cuentas creadas. ¡Excelente trabajo!
A veces algunos registros no pueden procesarse. Quizá el trabajo intentó crear registros Cuenta que ya existían. Quizá a los datos del trabajo les faltaban campos requeridos. En estos escenarios, puede pedir a Salesforce una lista de los registros que tuvieron un error durante el procesamiento, junto con más información sobre lo que falló. Echemos un vistazo a los registros incorrectos en la carpeta Bulk v2.
- Seleccione el recurso GET Obtener resultados de registros de trabajo con errores. Observe que el método HTTP es GET nuevamente.
- Haga clic en Enviar. Los resultados deben ser similares a los siguientes.

Postman proporciona una lista que contiene una lista de los registros que tuvieron errores durante el procesamiento, junto con el Id. de registro y el mensaje de error. En este caso, se insertaron todos sus registros correctamente, de modo que la lista de registros está vacía. ¡Excelente trabajo, capitán!