Recognize Bias in Artificial Intelligence
Learning Objectives
After completing this unit, you’ll be able to:
- Describe the role of data in developing an AI system.
- Understand the difference between what is ethical and what is legal.
- Identify types of bias that can enter an AI system.
- Find entry points for bias to enter an AI system.
Focus on Artificial Intelligence
Artificial intelligence can augment human intelligence, amplify human capabilities, and provide actionable insights that drive better outcomes for our employees, customers, partners, and communities.
We believe that the benefits of AI should be accessible to everyone, not just the creators. It’s not enough to deliver just the technological capability of AI. We also have an important responsibility to ensure that our customers can use our AI in a safe and inclusive manner for all. We take that responsibility seriously and are committed to providing our employees, customers, partners and community with the tools they need to develop and use AI safely, accurately, and ethically.
As you learn in the Artificial Intelligence Fundamentals badge, AI is an umbrella term that refers to efforts to teach computers to perform complex tasks and behave in ways that give the appearance of human agency. Training for such a task often requires large amounts of data, allowing the computer to learn patterns in the data. These patterns form a model that represents a complex system, much like you can create a model of our solar system. And with a good model, you can make good predictions (like predicting the next solar eclipse) or generate content (like write me a poem written by a pirate).
We don’t always know why a model is making a specific prediction or generating content a certain way. Frank Pasquale, author of The Black Box Society, describes this lack of transparency as the black box phenomenon. While companies that create AI can explain the processes behind their systems, it’s harder for them to tell what’s happening in real time and in what order, including where bias can be present in the model. AI poses unique challenges when it comes to bias and making fair decisions.
What Is Ethical vs. Legal?
Every society has laws citizens need to abide by. Sometimes, however, you need to think beyond the law to develop ethical technology. For example, US federal law protects certain characteristics that you generally can’t use in decisions involving hiring, promotion, housing, lending, or healthcare. These protected classes include sex, race, age, disability, color, national origin, religion or creed, and genetic information. If your AI models use these characteristics, you may be breaking the law. If your AI model is making a decision where it is legal to rely on these characteristics, it still may not be ethical to allow those kinds of biases. Issues related to protected classes can also cross over into the realm of privacy and legality, so we recommend taking our GDPR trail to learn more. Finally, it is also important to be aware of the ways that Einstein products may and may not be used in accordance with our Acceptable Use Policy.
The good news is that AI presents an opportunity to systematically address bias. Historically, if you recognized that your company’s decision-making resulted in a biased outcome as a result of individual decision-making, it was difficult to redesign the entire process and overcome this intrinsic bias. Now, with AI systems, we have the chance to bake fairness into the design and improve on existing practices.
In addition to carefully examining the legal and ethical implications of your AI models, you should assess whether your model is aligned with your business’s responsibility to respect and promote human rights. You should factor in international human rights law and the responsibilities the UN has laid out for businesses to respect human rights, which include a due diligence process to assess human rights impacts, act on the assessment, and communicate how the impacts are addressed.
Types of Bias to Look Out For
Bias manifests in a variety of ways. Sometimes it’s the result of systematic error. Other times it’s the result of social prejudice. Sometimes the distinction is blurry. With these two sources of bias in mind, let’s look at the ways in which bias can enter an AI system.
Measurement or Dataset Bias
When data are incorrectly labeled or categorized or oversimplified, it results in measurement bias. Measurement bias can be introduced when a person makes a mistake labeling data, or through machine error. A characteristic, factor, or group can be over- or underrepresented in your dataset.
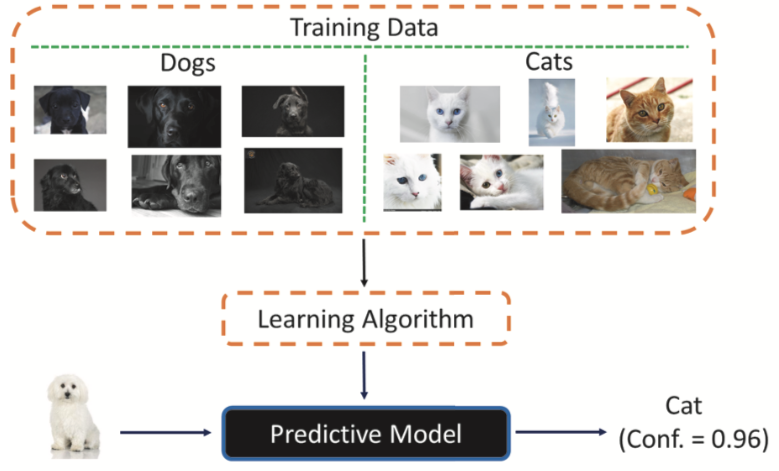
Let’s consider a harmless example: an image-recognition system for cats and dogs. The training data seems straightforward enough—photos of cats and dogs. But the image set includes only photos of black dogs, and either white or brown cats. Confronted with a photo of a white dog, the AI categorizes it as a cat. Although real-world training data is rarely so cut and dry, the results can be just as staggeringly wrong—with major consequences.
Type 1 vs. Type 2 Error
Think of a bank using AI to predict whether an applicant will repay a loan. If the system predicts that the applicant will be able to repay the loan but they don’t, it’s a false positive, or type 1 error. If the system predicts the applicant won’t be able to repay the loan but they do, that’s a false negative, or type 2 error. Banks want to grant loans to people they are confident can repay them. To minimize risk, their model is inclined toward type 2 errors. Even so, false negatives harm applicants the system incorrectly judges as unable to repay.

Association Bias
Data that are labeled according to stereotypes is an example of association bias. Search most online retailers for “toys for girls" and you get an endless assortment of cooking toys, dolls, princesses, and pink. Search “toys for boys," and you see superhero action figures, construction sets, and video games.
Confirmation Bias
Confirmation bias labels data based on preconceived ideas. The recommendations you see when you shop online reflect your purchasing habits, but the data influencing those purchases already reflect what people see and choose to buy in the first place. You can see how recommendation systems reinforce stereotypes. If superheroes don’t appear on a website’s ‘toys for girls” section, a shopper is unlikely to know they’re elsewhere on the site, much less purchase them.
Automation Bias
Automation bias imposes a system’s values on others. Take, for instance, a beauty contest judged by AI in 2016. The goal was to declare the most beautiful women with some notion of objectivity. But the AI in question was trained primarily on images of white women and its learned definition of "beauty" didn't include features more common in people of color. As a result, the AI chose mostly white winners, translating a bias in training data into real world outcomes.
Automation bias isn't limited to AI. Take the history of color photography. Starting in the mid-1950s, Kodak provided photo labs that developed their film with an image of a fair-skinned employee named Shirley Page that was used to calibrate skin tones, shadows, and light. While different models were used over time, the images became known as "Shirley cards." Shirley's skin tone, regardless of who she was (and she was initially always white) was considered standard. As Lorna Roth, a media professor at Canada's Concordia University told NPR, when the cards were first created, "the people who were buying cameras were mostly Caucasian people. And so I guess they didn't see the need for the market to expand to a broader range of skin tones." In the 1970s, they started testing on a variety of skin tones and made multiracial Shirley cards.
Societal Bias
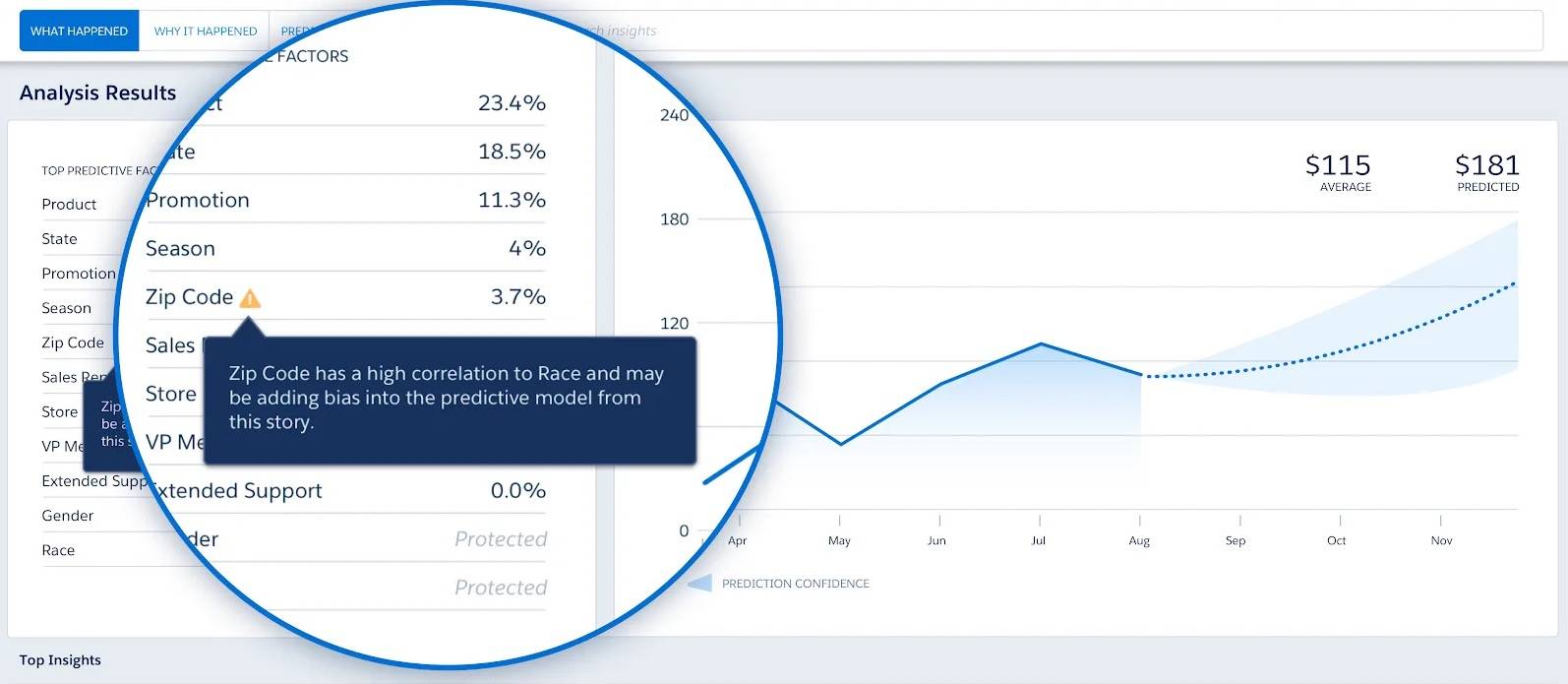
Societal bias reproduces the results of past prejudice toward historically marginalized groups. Consider redlining. In the 1930s, a federal housing policy color-coded certain neighborhoods in terms of desirability. The ones marked in red were considered hazardous. The banks often denied access to low-cost home lending to minority groups residents of these red marked neighborhoods. To this day, redlining has influenced the racial and economic makeup of certain zip codes, so that zip codes can be a proxy for race. If you include zip codes as a data point in your model, depending on the use case you could inadvertently be incorporating race as a factor in your algorithm’s decision-making. Remember that it is also illegal in the US to use protected categories like age, race, or gender in making many financial decisions.
Survival or Survivorship Bias
Sometimes, an algorithm focuses on the results of those were selected, or who survived a certain process, at the expense of those who were excluded. Let’s look at hiring practices. Imagine that you’re the hiring director of a company, and you want to figure out whether you should recruit from a specific university. You look at current employees hired from such-and-such university. But what about the candidates that weren’t hired from that university, or who were hired and subsequently let go? You see the success of only those who “survived.”

Interaction Bias
Humans create interaction bias when they interact with or intentionally try to influence AI systems and create biased results. An example of this is when people intentionally try to teach chatbots bad language.
How Does Bias Enter the System?
You know that bias can enter an AI system through a product’s creators, through training data (or lack of information about all the sources that contribute to a dataset), or from the social context in which an AI is deployed.
Assumptions
Before someone starts building a given system, they often make assumptions about what they should build, who they should build for, and how it should work, including what kind of data to collect from whom. This doesn’t mean that the creators of a system have bad intentions, but as humans, we can’t always understand everyone else’s experiences or predict how a given system will impact others. We can try to limit our own assumptions from entering into a product by including diverse stakeholders and participants in our research and design processes from the very beginning. We should also strive to have diverse teams working on AI systems.
Training Data
AI models need training data, and it’s easy to introduce bias with the dataset. If a company historically hires from the same universities, same programs, or along the same gender lines, a hiring AI system will learn that those are the best candidates. The system will not recommend candidates that don’t match those criteria.
Model
The factors you use to train an AI model, such as race, gender, or age, can result in recommendations or predictions that are biased against certain groups defined by those characteristics. You also need to be on the lookout for factors that function as proxies for these characteristics. Someone’s first name, for example, can be a proxy for gender, race, or country of origin. For this reason, Einstein products don't use names as factors in its Lead and Opportunity Scoring model.
Human Intervention (or Lack Thereof)
Editing training data directly impacts how the model behaves, and can either add or remove bias. We might remove poor-quality data or overrepresented data points, add labels or edit categories, or exclude specific factors, such as age and race. We can also leave the model as-is, which, depending on the circumstances, can leave room for bias.
The stakeholders in an AI system should have the option to give feedback on its recommendations. This can be implicit (say, the system recommends a book the customer might like and the customer does not purchase it) or explicit (say, the customer gives a thumbs up to a recommendation). This feedback trains the model to do more or less of what it just did. According to GDPR, EU citizens must also be able to correct incorrect information a company has about them and ask for that company to delete their data. Even if not required by law, this is best practice as it ensures your AI is making recommendations based on accurate data and is ensuring customer trust.
AI Can Magnify Bias
Training AI models based on biased datasets often amplifies those biases. In one example, a photo dataset had 33 percent more women than men in photos involving cooking, but the algorithm amplified that bias to 68 percent. To learn more, see the blog post in the resources section.