Implement Scaling and Plan for Resilience, Middleware, and Networking
Learning Objectives
After completing this unit, you’ll be able to:
- Describe two scaling techniques.
- List three situations where caching can’t help.
- Discuss resilience planning.
- Explain the importance of middleware tuning.
- Explain how networking is best supported.
Caching Can’t Always Help
Vijay knows that the appropriate use of cache throughout the infrastructure can prevent a lot of requests from ever reaching the application cluster. But here are some cases where cache can’t help.
- There’s an increase in requests to endpoints that are not cached by design (for example, POST requests performing account creations during a big sale event).
- The cache has been flushed/invalidated.
- The cache is full or incorrectly sized, causing a low cache hit ratio.
- A marketing campaign contains links with unique parameters that evade the cache, for example
/myAPI_v1/categories/mens?emailAddress=customer123@email.com.
These solutions can pick up where caching falls short.
- Scaling
- Resilience planning
- Middleware choices
- Networking choices and support
Scaling
Vijay wants his infrastructure to scale up quickly to avoid performance degradations or service disruptions. Vijay considers horizontal and vertical scaling techniques for his production environment. He also considers waiting-room technologies to handle unexpected resource usage that can affect application performance.
Horizontal Scaling
With horizontal scaling, additional application nodes are allocated to a cluster to achieve optimal performance under higher workloads. For example, if there are four application nodes in the cluster with four CPUs and 4GB of RAM, you provision more application nodes to the cluster instead of allocating more resources to existing nodes.
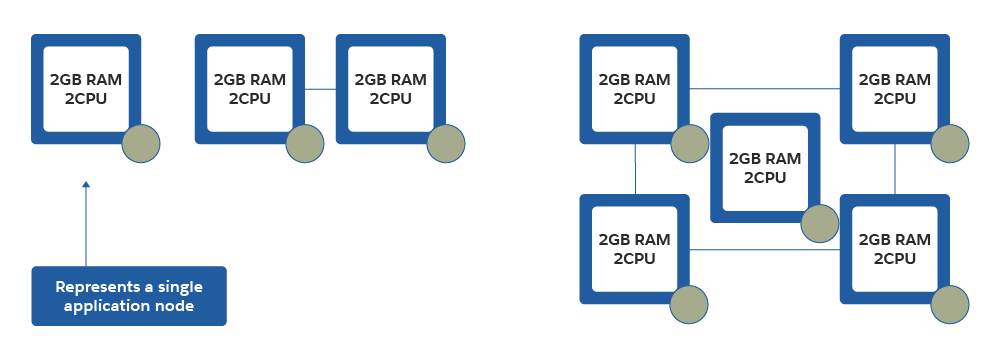 Let’s say an application uses a thread pool to manage client tasks with plenty of CPU and memory available before the thread pool becomes exhausted. Horizontal scaling adds application nodes to increase the number of available threads in the pool.
Let’s say an application uses a thread pool to manage client tasks with plenty of CPU and memory available before the thread pool becomes exhausted. Horizontal scaling adds application nodes to increase the number of available threads in the pool.
While horizontal scaling increases the physical system resources available to applications, periods of unexpected traffic put more pressure on other systems such as your database and third-party endpoints. Vijay needs to understand the constraints of these systems so that as demand increases, the other systems can also handle the increase.
Kubernetes and Heroku provide autoscaling features that let you scale an application cluster horizontally based on user defined conditions, or even by custom application metrics. See Horizontal Pod Autoscaler and Scaling Your Dyno Formation for more information.
Heroku Scaling
When you scale an application cluster horizontally, multiple applications can process requests when they need more processing power. But this can still result in poor performance if you don’t implement caching properly throughout the applications and infrastructure.
Vertical Scaling
Vertical scaling is where you add more physical resources to the application cluster to achieve optimal performance under higher workloads. For example, if there are four application nodes in the cluster with four CPUs and 4GB of RAM, you scale the cluster vertically, allocating the instance eight CPUs and 16GB of RAM to handle a higher workload.
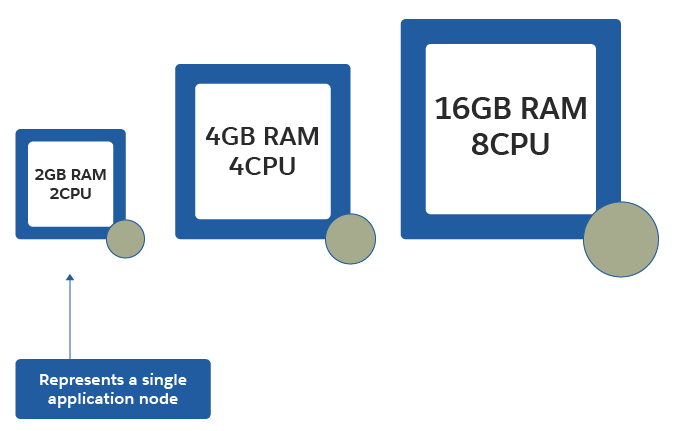 You might need to restart the application nodes to apply resource configuration changes. And this might be OK if a single node or fixed-size cluster can handle a higher workload simply by adding more resources. Vertical scaling is a common practice for scaling datastore applications such as Redis, which might only be deployed as a single node or fixed-size cluster.
You might need to restart the application nodes to apply resource configuration changes. And this might be OK if a single node or fixed-size cluster can handle a higher workload simply by adding more resources. Vertical scaling is a common practice for scaling datastore applications such as Redis, which might only be deployed as a single node or fixed-size cluster.
Waiting Rooms
Sometimes it’s not enough to spin up additional application nodes to sustain levels of traffic that are beyond the bounds of what you’ve tested or expected. Waiting room technologies such as Queue-it integrate with your CDN, so you can control the level of traffic allowed to reach your application, while overflow users are placed in a queue. Waiting room technology is great for a new implementation when you don’t know what to expect for traffic levels or if traffic levels are higher than the application supports.
B2C Commerce Scaling
The B2C Commerce platform uses horizontal scaling techniques. As system resource usage increases, B2C Commerce adds application nodes to the cluster to ensure that storefront performance remains the same. Vijay plans to use a similar strategy for his custom head to ensure his applications scale to meet shopper traffic demands.
Vijay investigates the boundaries of his application stack to determine key autoscaling triggers that ensure his application can withstand sudden bursts of traffic. He plans to deploy his application stack using containers. This is a standard way to divide applications into distributed objects (or containers), so that he can place them on different physical and virtual machines, in the cloud or not. This flexibility lets him better manage his application and make it more fault tolerant.
Container orchestration is handled by Kubernetes. This high-level architecture diagram (from the previous unit) shows how Kubernetes interacts with the node.js APIs. Tools like this help Vijay provision applications, balance resources among a cluster of servers, monitor platform health, balance loads, and more.
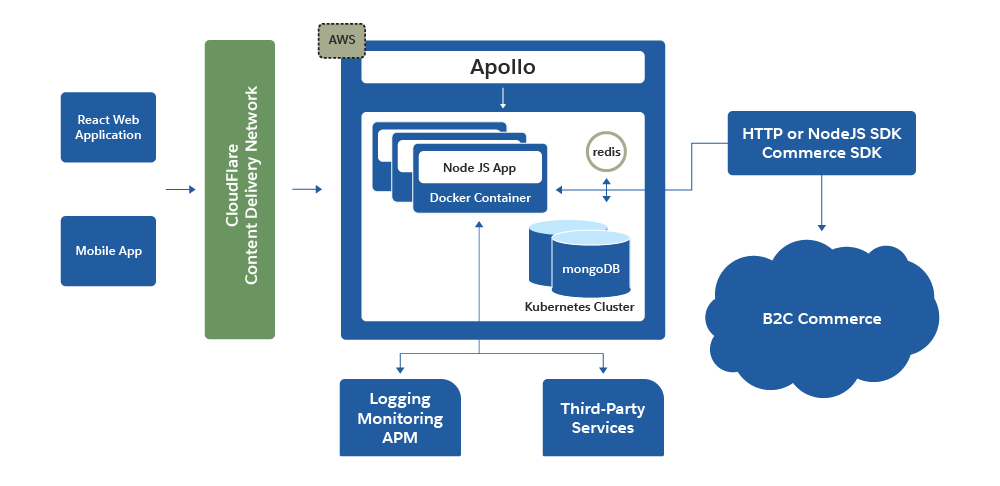

Plan for Resilience
Resilience is the ability to recover quickly from difficulties. Vijay is all about being resilient—especially when it comes to his company’s B2C Commerce storefront. Not only does every component within the B2C Commerce infrastructure have redundancy in the event of single node failures, but the infrastructure also has standby systems running in separate data centers to minimize interruption in case of a disaster.
B2C Commerce applications are designed to fail fast in the event of known service degradations. For example, in Cloud Kicks’s traditional storefront implementation, B2C Commerce prevents calls to third parties if their service is performing poorly. This prevents application threads from being tied up for long periods of time trying to avoid a performance degradation or unavailability.
This same quality of service is available when Vijay calls B2C Commerce APIs from a custom head. In this case, however, he must consider how to provide the same level of service within the custom head.
Failure and Recovery
He needs to plan for both single node failures and entire infrastructure outages to ensure his application stays available in the event of a disaster. Even a single node failure can significantly impact his application. For example, if he load balances between two web servers to serve traffic coming into the application, he must consider the impact to the application if one or both web servers become unavailable.
He must have a recovery plan for these situations, whether he uses autoscaling policies to provision new applications or has a 24/7 team in place to quickly react in the event of a partial or total service disruption.
Built in Resilience
Vijay designs his applications to be resilient enough to handle service disruptions gracefully without causing negative shopper experiences. For example, if the Cloud Kicks loyalty service becomes too slow to respond to requests, he wants circuit breaker logic to block calls to the point balance check (how many points the shopper has) when a shopper logs in to the application until the service recovers.
Here’s his logic: A shopper who can’t see their loyalty balance after logging in is more likely to continue shopping than a shopper who can’t log in at all.
Many cloud providers offer flow control/circuit breaker functionality within their API gateways, or have libraries, such as resilience 4j, for building the functionality into custom back-end systems.
Middleware
B2C Commerce uses several middleware components that are configured for optimal performance and scale. Tuning these components involves trial and error via load testing before finding the optimal configuration. Middleware can be web servers, relational database management systems (RDBMS), runtime containers such as Docker, operating systems, and custom application parameters.
Vijay wants a middleware architecture that best suits the needs of his custom head and experts within his or his partners’ organization who understand middleware deployment, maintenance, and configuration. A highly performant and scalable application can still experience performance losses if you don’t configure or maintain these components properly.
Networking
Vijay relies on the B2C Commerce network team to understand how traffic flows through the B2C Commerce network and infrastructure. Application components deployed on different networks across different cloud providers can be extremely difficult to troubleshoot. Understanding how these components relate to applications and infrastructure is key to success, especially with tricky network issues. As Vijay designs his new implementation, he makes sure his team includes in-house network experts who can capture and review network traces for performance or availability issues.
Next Steps
In this unit, you explored solutions that can pick up where caching falls short, such as scaling, resilience planning, and networking choices. Next, you learn how to log and monitor for application performance.