Die Antwort-Journey
Lernziele
Nachdem Sie diese Lektion abgeschlossen haben, sind Sie in der Lage, die folgenden Aufgaben auszuführen:
- Beschreiben der Antwort-Journey
- Erläutern der Null-Datenspeicherung
- Beschreiben, warum die Erkennung toxischer Sprache wichtig ist

Kurze Wiederholung der Aufforderungs-Journey
Sie haben bereits die sorgfältigen Schritte gesehen, die Salesforce mit der Einstein-Vertrauensebene unternimmt, um Jessicas Kundendaten und deren Unternehmensdaten zu schützen. Bevor Sie mehr erfahren, sollten wir die Aufforderungs-Journey noch einmal kurz wiederholen.
- Eine Aufforderungsvorlage wurde automatisch aus Service Replies abgerufen, um Jessica bei ihrem Kundenservicevorgang zu unterstützen.
- Die Briefvorlagenfelder in der Aufforderungsvorlage wurden mit vertrauenswürdigen, sicheren Daten aus Jessicas Organisation ausgefüllt.
- Relevante Knowledge-Artikel und Details aus anderen Objekten wurden abgerufen und eingefügt, um der Aufforderung mehr Kontext zu geben.
- Personenbezogene Informationen wurden maskiert.
- Die Aufforderung wurde mit zusätzlichen Schutzmaßnahmen versehen, um ihn weiter zu schützen.
- Nun ist die Aufforderung bereit, über das sichere Gateway an das externe LLM übertragen zu werden.
Das sichere LLM-Gateway
Nachdem die Aufforderung mit relevanten Daten gefüllt und Schutzmaßnahmen getroffen wurden, kann sie die Salesforce Trust-Grenze verlassen, indem sie durch das sichere LLM-Gateway an die verbundenen LLMs übertragen wird. In diesem Fall ist Jessicas Organisation mit dem LLM OpenAI verbunden. OpenAI verwendet diese Aufforderung, um eine relevante, hochwertige Antwort für Jessica zu generieren, die sie im Gespräch mit ihrem Kunden einsetzen kann.
Die Null-Datenspeicherung
Wenn Jessica ein kundenorientiertes LLM-Tool wie z. B. einen generativen KI-Chatbot ohne robuste Vertrauensebene verwenden würde, könnte ihre Aufforderung, einschließlich sämtlicher Daten ihres Kunden, und sogar die Antwort des LLM, vom LLM für das Modelltraining gespeichert werden. Wenn Salesforce jedoch eine Partnerschaft mit einem externen API-basierten LLM eingeht, fordern wir eine Vereinbarung darüber, dass die gesamte Interaktion sicher bleibt – wir nennen das die Null-Datenspeicherung. Unsere Null-Datenspeicherungsrichtlinie bedeutet, dass keinerlei Kundendaten, einschließlich des Aufforderungstexts und der generierten Antworten, außerhalb von Salesforce gespeichert werden.

Dies funktioniert wie folgt: Jessicas Aufforderung wird an ein LLM übermittelt. Nicht vergessen: diese Aufforderung ist eine Anweisung. Das LLM nimmt diese Aufforderung und generiert gemäß der Aufforderungsanweisungen und unter Einhaltung der Schutzmaßnahmen eine oder mehrere Antworten.
Normalerweise würde OpenAI Aufforderungen und Aufforderungsantworten für eine gewisse Zeit aufbewahren, um sie auf Missbrauch zu überwachen. Die unglaublich leistungsfähigen LLMs von OpenAI überprüfen, ob irgendetwas Ungewöhnliches mit seinen Modellen passiert, beispielsweise Prompt Injection-Angriffe, von denen Sie in der letzten Einheit gehört haben. Unsere Null-Datenspeicherungsrichtlinie verhindert jedoch, dass die LLM-Partner irgendwelche Daten aus der Interaktion aufbewahren. Wir haben vereinbart, dass wir diese Überprüfung übernehmen.
Wir erlauben OpenAI nicht, Daten zu speichern. Wenn also eine Aufforderung an OpenAI gesendet wird, vergisst das Modell die Aufforderung und die Antworten, sobald die Antwort zurück an Salesforce gesendet wird. Dies ist wichtig, weil es Salesforce erlaubt, seine eigenen Inhalte und die Missbrauchsüberprüfung zu handeln. Außerdem müssen sich Benutzer wie Jessica keine Gedanken darüber machen, ob LLM-Anbieter die Daten ihrer Kunden aufbewahren und verwenden.
Die Antwort-Journey
Bei unserem ersten Zusammentreffen mit Jessica haben wir erwähnt, dass sie etwas besorgt ist, ob die von der KI generierten Antworten ihrer Vorstellung in Sachen Gewissenhaftigkeit entsprechen. Sie weiß nicht so recht, was sie erwarten soll, doch sie muss sich keine Sorgen machen, denn die Einstein-Vertrauensebene deckt dies ab. Er enthält mehrere Funktionen, die dazu beitragen, dass das Gespräch personalisiert und professionell bleibt.

Bisher wurde die Aufforderungsvorlage aus Jessicas Gespräch mit ihrem Kunden mit relevanten Kundeninformationen und nützlichem Kontext im Zusammenhang mit dem Vorgang gefüllt. Jetzt hat das LLM diese Details verarbeitet und eine Antwort zurück in die Salesforce Trust-Grenze übermittelt. Jessica bekommt die Antwort allerdings noch nicht zu sehen. Der Ton der Antwort ist zwar freundlich und der Inhalt korrekt, muss aber noch von der Vertrauensebene auf unbeabsichtigten Output geprüft werden. Zudem enthält die Antwort noch Blöcke mit maskierten Daten, und das würde Jessica als viel zu unpersönlich empfinden, um es mit ihrem Kunden zu teilen. Die Vertrauensebene muss noch einige weitere wichtige Aktionen durchführen, bevor Jessica die Antwort zu sehen bekommt.

Hallo <NAME_1>! Schön, mit Ihnen zu sprechen. Es tut mir leid, dass Sie heute Probleme mit dem Upgrade Ihrer Kreditkarte haben. Sie sind schon über fünf Jahre geschätzter Kunde von <COMPANY_1>, und wir werden uns bemühen, dieses Problem rasch zu beheben.
Ja, bei einigen unserer Kreditkartenangebote muss eine Mindestbonität erfüllt sein*. Können Sie mir mehr darüber sagen, welche Probleme Sie bei der Beantragung haben?
Quelle: Mindestanforderungen für Cumulus Karten-Upgrades
Erkennung toxischer Sprache und Entfernen der Datenmaskierung
Bei der Rücksendung der Antwort des LLMs auf Jessicas Gespräch in die Salesforce Trust-Grenze geschehen zwei wichtige Dinge. Erstens schützt die Erkennung toxischer Sprache Jessica und ihre Kunden vor toxischen Aussagen. Was das ist, fragen Sie sich? Die Vertrauensebene verwendet maschinelle Lernmodelle, um toxische Inhalte in Aufforderungen und Antworten zu identifizieren und in fünf Kategorien einzuordnen: Gewalt, Sexualität, Obszönität, Hass und physisch. Der Toxizitätsgesamtwert umfasst die Werte aller erkannten Kategorien und ergibt eine Gesamtbewertung zwischen 0 und 1, wobei 1 für die höchste Toxizität steht. Der Wert für die ursprüngliche Antwort wird zusammen mit der Antwort an die Anwendung zurückgegeben, die sie angefordert hat – in diesem Fall "Service Replies".
Bevor die Aufforderung an Jessica weitergegeben wird, muss dann die Vertrauensebene die bereits angesprochene Maskierung der Daten aufheben, damit die Antwort persönlich und für Jessicas Kunden relevant ist. Die Vertrauensebene verwendet die gleichen tokenisierten Daten, die wir bei der ursprünglichen Maskierung der Daten gespeichert haben, um die Maskierung aufzuheben. Sobald die Daten demaskiert sind, wird die Antwort für Jessica freigegeben.
Beachten Sie auch den Link "Source:" (Quelle) am Ende der Antwort. Die Funktion zur Erstellung von Knowledge erhöht die Glaubwürdigkeit von Antworten, indem sie Links zu hilfreichen Artikeln hinzufügt.

Hallo Dennis Maxfield! Schön, mit Ihnen zu sprechen. Es tut mir leid, dass Sie heute Probleme mit dem Upgrade Ihrer Kreditkarte haben. Sie sind schon über fünf Jahre geschätzter Kunde von Cumulus Financial, und wir werden uns bemühen, dieses Problem rasch zu beheben.
Ja, bei einigen unserer Kreditkartenangebote muss eine Mindestbonität erfüllt sein*. Können Sie mir mehr darüber sagen, welche Probleme Sie bei der Beantragung haben?
Quelle: Mindestanforderungen für Cumulus Karten-Upgrades
Feedback-Framework
Als Jessica die Antwort zum ersten Mal sieht, lächelt sie. Sie ist beeindruckt von der Qualität und der Detailgenauigkeit der Antwort, die sie vom LLM erhalten hat. Ihr gefällt zudem, wie gut die Antwort ihrem persönlichen Stil bei der Vorgangsbearbeitung entspricht. Jessica überprüft die Antwort, bevor sie sie an ihren Kunden sendet, und sieht, dass sie die Antwort entweder unverändert akzeptieren, sie vor dem Senden bearbeiten oder ganz ignorieren kann.
Sie kann auch ein qualitatives Feedback in Form eines "Daumen nach oben" oder "Daumen nach unten" geben und, wenn die Antwort nicht hilfreich war, einen Grund dafür angeben. Dieses Feedback wird gesammelt und kann in Zukunft auf sichere Weise genutzt werden, um die Qualität von Aufforderungen zu verbessern.

Aktivierungsprotokoll
Es gibt noch einen letzten Teil der Vertrauensebene, den wir Ihnen zeigen möchten. Erinnern Sie sich an die Null-Datenspeicherungsrichtlinie, über die wir zu Beginn dieser Einheit gesprochen haben? Da die Vertrauensebene die Bewertung und Eindämmung toxischer Sprache intern erledigt, verfolgen wir jeden Schritt, der während des gesamten Wegs von Aufforderung zu Antwort getan wird.
Alles, was während der gesamten Interaktion zwischen Jessica und ihrem Kunden passiert ist, sind mit einem Zeitstempel versehene Metadaten, die wir in einem Prüfprotokoll erfassen. Dazu gehören die Aufforderung, die ursprüngliche ungefilterte Antwort, alle Toxizitätsbewertungen und das im Verlauf der Interaktion gesammelte Feedback. Das Prüfprotokoll der Einstein-Vertrauensebene bietet eine weitere Ebene der Verantwortlichkeit, sodass Jessica sicher sein kann, dass die Daten ihres Kunden geschützt sind.
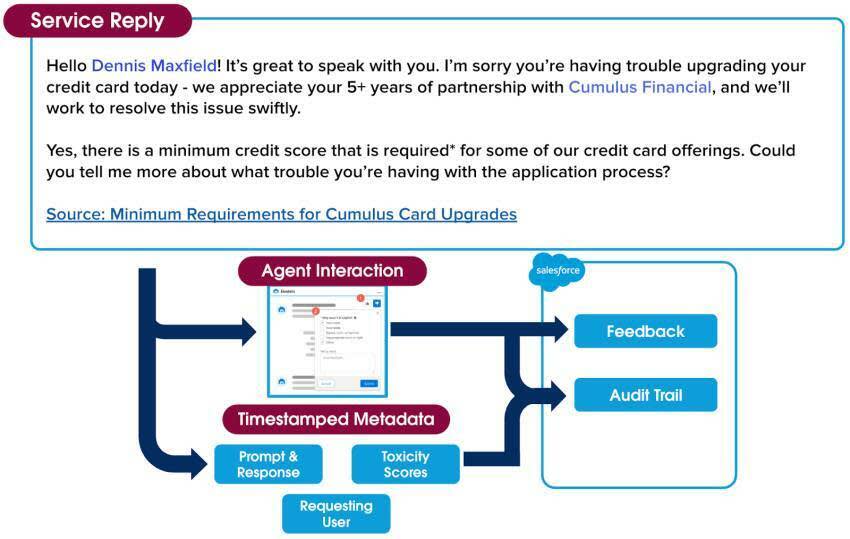
Seit Beginn des Gesprächs zwischen Jessica und ihrem Kunden ist also viel passiert – gedauert hat das Ganze aber nur einen Wimpernschlag. In Sekundenschnelle wurde aus ihrem Gespräch eine per Chat aufgerufene Aufforderung, die die Sicherheit des gesamten Prozesses der Vertrauensebene durchlief und zu einer relevanten, professionellen Antwort wurde, die sie an den Kunden weitergeben kann.
Sie schließt den Vorgang in der Gewissheit ab, dass ihr Kunde mit der Antwort und seinem Kundenserviceerlebnis zufrieden ist. Und das Allerbeste ist, dass sie sich jetzt sogar darauf freut, die leistungsfähige generative KI von Service Replies weiterhin zu nutzen, da sie zuversichtlich ist, dass sie ihre Vorgänge damit schneller abschließen und ihre Kunden zufrieden stellen kann.
Jede einzelne der generativen KI-Lösungen von Salesforce nimmt denselben Weg durch die Vertrauensebene. Alle unsere Lösungen sind sicher, und Sie können sich darauf verlassen, dass Ihre Daten und die Daten Ihrer Kunden geschützt sind.
Herzlichen Glückwunsch, Sie wissen jetzt wie die Einstein-Vertrauensebene funktioniert! Wenn Sie mehr darüber erfahren möchten, was Salesforce in puncto Vertrauen und generative KI unternimmt, absolvieren Sie den Trailhead-Badge Verantwortungsbewusste Entwicklung künstlicher Intelligenz.
Ressourcen
- Trailhead: Verantwortungsbewusste Entwicklung künstlicher Intelligenz
- Salesforce-Hilfe: Einstein Generative AI & Trust