Kennenlernen von KI-Techniken und -Anwendungen
Lernziele
Nachdem Sie diese Lektion abgeschlossen haben, sind Sie in der Lage, die folgenden Aufgaben auszuführen:
- Identifizieren praktischer Anwendungsfälle für KI
- Erläutern der Grenzen von KI-Modellen und ChatGPT
- Erklären des Datenlebenszyklus für KI und die Bedeutung von Datenschutz und Sicherheit bei KI-Anwendungen
Trailcast
Wenn Sie sich eine Audioaufzeichnung dieses Moduls anhören möchten, nutzen Sie den nachstehenden Player. Denken Sie nach dem Anhören dieser Aufzeichnung daran, zur jeweiligen Lektion zurückzukehren, sich die Ressourcen anzusehen und die zugehörigen Aufgaben zu absolvieren.
Technologien mit künstlicher Intelligenz
Künstliche Intelligenz ist ein weites Feld mit dem Ziel, Maschinen wie Menschen lernen und denken zu lassen. Und es gibt viele Technologien, die KI beinhalten.
-
Maschinelles Lernen nutzt verschiedene mathematische Algorithmen, um Erkenntnisse aus Daten zu gewinnen und Vorhersagen zu treffen.
-
Deep Learning verwendet eine spezielle Art von Algorithmus, ein sogenanntes neuronales Netz, um Verbindungen zwischen einer Reihe von Eingaben und Ausgaben zu finden. Deep Learning wird umso wirkungsvoller und effizienter, je größer die Datenmenge ist.
-
Natural Language Processing ist eine Technologie, die es Maschinen ermöglicht, menschliche Sprache als Eingabe zu akzeptieren und entsprechend Aktionen durchzuführen.
-
Große Sprachmodelle (LLMs) sind fortschrittliche Computermodelle, die dafür konzipiert sind, von Menschen verfasste Texte zu verstehen und menschenähnliche Texte zu erstellen.
-
Computer-Vision ist eine Technologie, mit der Maschinen visuelle Informationen interpretieren können.
-
Robotik ist eine Technologie, die es Maschinen ermöglicht, physische Aufgaben auszuführen.
Weitere Informationen dazu finden Sie im Trailhead-Modul Künstliche Intelligenz – Grundlagen.
Maschinelles Lernen (ML) kann je nach Lernansatz und Art des zu lösenden Problems in verschiedene Kategorien unterteilt werden.
-
Beaufsichtigtes Lernen: Bei diesem Ansatz für maschinelles Lernen lernt ein Modell anhand gekennzeichneter Daten und trifft auf der Grundlage der gefundenen Muster Vorhersagen. Das Modell kann dann anhand der beim Trainieren erlernten Muster Vorhersagen treffen oder neue, ihm noch nicht bekannte Daten klassifizieren.
-
Nicht beaufsichtigtes Lernen: Hier lernt das Modell anhand nicht gekennzeichneter Daten und findet Muster und Beziehungen ohne vordefinierte Ausgaben. Das Modell lernt, Ähnlichkeiten zu erkennen, ähnliche Datenpunkte zu gruppieren oder zugrundeliegende versteckte Muster im Datenset zu finden.
-
Bestärkendes Lernen (Reinforcement Learning): Bei dieser Art des Lernens lernt ein Software-Agent nach dem Prinzip Versuch und Irrtum, indem er Aktionen durchführt, um die von der Umgebung erhaltenen Belohnungen zu maximieren. Bestärkendes Lernen wird häufig in Szenarien eingesetzt, in denen eine optimale Entscheidungsstrategie durch Versuch und Irrtum erlernt werden muss, wie z. B. in der Robotik, bei Spielen und autonomen Systemen. Der Software-Agent probiert verschiedene Aktionen aus und lernt aus den Konsequenzen dieser Aktionen, um seinen Entscheidungsprozess zu optimieren.
In den letzten Jahren wurden AutoML- und No-Code-KI-Tools wie OneNine AI und Salesforce AI eingeführt, um den Aufbau einer ganzen Pipeline für maschinelles Lernen mit minimalem menschlichen Eingriff zu automatisieren.
Die Rolle von maschinellem Lernen
Maschinelles Lernen ist ein Teilbereich der künstlichen Intelligenz. Hier werden statistische Algorithmen verwendet, damit Computer aus Daten lernen können, ohne explizit programmiert zu werden. Mithilfe von Algorithmen werden Modelle erstellt, die auf der Grundlage von Eingaben Vorhersagen oder Entscheidungen treffen können.
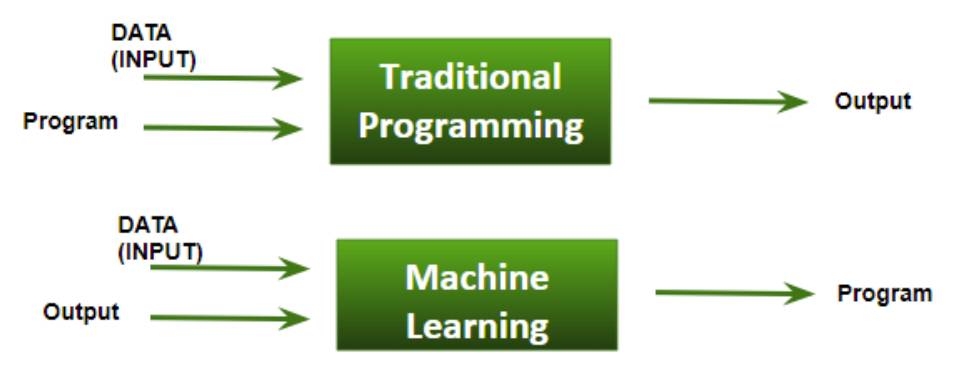
Maschinelles Lernen im Vergleich zu Programmieren
Beim traditionellen Programmieren muss der Programmierer das Problem und die angestrebte Lösung genau verstehen. Beim maschinellen Lernen lernt der Algorithmus aus den Daten und erstellt seine eigenen Regeln oder Modelle zur Lösung des Problems.
Bedeutung von Daten bei maschinellem Lernen
Daten sind das "Futter" für maschinelles Lernen. Die Qualität und Quantität der Daten, die zum Trainieren des Modells für maschinelles Lernen verwendet werden, können einen erheblichen Einfluss auf dessen Genauigkeit und Effektivität haben. Es ist wichtig sicherzustellen, dass die verwendeten Daten relevant, genau, vollständig und nicht durch Bias verzerrt sind.
Datenqualität und Grenzen des maschinellen Lernens
Um die Datenqualität zu gewährleisten, müssen die Daten bereinigt und vorverarbeitet werden, um Rauschen (unerwünschte oder bedeutungslose Informationen), fehlende Werte oder Ausreißer zu entfernen.
Maschinelles Lernen ist zwar ein leistungsfähiges Tool für die Lösung eines breiten Spektrums von Problemen, aber es gibt auch Grenzen für seine Effektivität, wie z. B. Überanpassung, Unteranpassung und Bias.
- Eine Überanpassung (Overfitting) liegt vor, wenn das Modell zu komplex ist und die Trainingsdaten zu genau abbildet, was zu einer schlechten Verallgemeinerung führt.
- Von Unteranpassung (Underfitting) spricht man, wenn das Modell zu einfach ist und die zugrunde liegenden Muster in den Daten nicht erfasst.
-
Bias tritt auf, wenn das Modell anhand von Daten trainiert wird, die nicht repräsentativ für die reale Zielgruppe sind.
Grenzen für maschinelles Lernen ergeben sich aus Qualität und Quantität der verwendeten Daten, der mangelnden Transparenz komplexer Modelle, Schwierigkeiten bei der Verallgemeinerung auf neue Situationen, Herausforderungen beim Umgang mit fehlenden Daten und potenziellen Verzerrungen bei Vorhersagen durch Bias.
Maschinelles Lernen ist zwar ein leistungsfähiges Werkzeug, doch Sie sollten sich unbedingt dieser Einschränkungen bewusst sein und sie beim Design und der Verwendung von ML-Modellen berücksichtigen.
Prädiktive und generative KI im Vergleich
Unter prädiktiver KI versteht man die Verwendung von Algorithmen für maschinelles Lernen, um Vorhersagen oder Entscheidungen auf der Grundlage von Dateneingaben zu treffen. Prädiktive KI kann in einer Vielzahl von Anwendungen eingesetzt werden, z. B. für die Betrugserkennung, die medizinische Diagnostik und Vorhersagen zur Kundenabwanderung.
Unterschiedliche Ansätze, unterschiedlicher Zweck
Prädiktive KI ist eine Art des maschinellen Lernens, bei dem ein Modell trainiert wird, damit es auf der Grundlage von Daten Vorhersagen oder Entscheidungen trifft. Das Modell erhält ein Eingabedatenset und lernt, Muster in den Daten zu erkennen, die ihm ermöglichen, genaue Vorhersagen für neue Eingaben zu treffen. Prädiktive KI wird häufig in Anwendungen wie Bilderkennung, Spracherkennung und Natural Language Processing eingesetzt.
Im Gegensatz dazu erstellt generative KI neue Inhalte wie Bilder, Videos oder Texte auf der Grundlage einer vorgegebenen Eingabe. Anstatt Vorhersagen auf der Basis vorhandener Daten zu treffen, erstellt generative KI neue Daten, die den Eingabedaten ähneln. Dies kann für eine Vielzahl von Anwendungen genutzt werden, wie etwa Kunst, Musik und kreatives Schreiben. Ein gängiges Beispiel für generative KI ist die Verwendung neuronaler Netze, um auf der Grundlage eines vorgegebenen Eingabedatensets neue Bilder zu generieren.
Prädiktive und generative KI sind zwar unterschiedliche KI-Ansätze, schließen sich jedoch nicht gegenseitig aus. Tatsächlich nutzen viele KI-Anwendungen sowohl prädiktive als auch generative Verfahren, um ihre Ziele zu erreichen. Ein Chatbot könnte beispielsweise prädiktive KI verwenden, um Eingaben eines Benutzers zu verstehen, und generative KI, um eine Antwort zu generieren, die der menschlichen Sprache ähnlich ist. Insgesamt hängt die Entscheidung für prädiktive oder generative KI von den speziellen Zielen der Anwendung und des Projekts ab.
Sie haben jetzt einiges über prädiktive und generative KI und ihre Unterschiede erfahren. Die folgende Tabelle enthält einen kurzen Überblick über die beiden Verfahren.
Prädiktive KI |
Generative KI |
|---|---|
Kann genaue Vorhersagen auf der Grundlage gekennzeichneter Daten treffen |
Kann neuen und kreativen Inhalt erstellen |
Kann zur Lösung vieler verschiedener Probleme eingesetzt werden, z. B. für die Betrugserkennung, die medizinische Diagnostik und Vorhersagen zur Kundenabwanderung |
Kann für eine Vielzahl von kreativen Anwendungen genutzt werden, wie etwa Kunst, Musik und Schreiben |
Eingeschränkt durch die Qualität und Quantität der verfügbaren gekennzeichneten Daten |
Kann auf der Grundlage der Eingabedaten durch Bias verzerrten oder unangemessenen Inhalt generieren |
Hat eventuell Schwierigkeiten mit Vorhersagen außerhalb der gekennzeichneten Daten, anhand derer das Modell trainiert wurde |
Hat eventuell Schwierigkeiten damit, den Kontext zu verstehen oder kohärenten Inhalt zu erstellen |
Training und Bereitstellung erfordern möglicherweise erhebliche Rechenressourcen |
Eignet sich eventuell nicht für alle Anwendungen, besonders wenn Genauigkeit gefragt ist |
Einschränkungen von generativer KI
Generative KI erstellt neue Inhalte wie Bilder oder Texte auf der Grundlage einer vorgegebenen Eingabe. ChatGPT ist beispielsweise ein generatives KI-Tool, das große Sprachmodelle (LLMs) nutzt, um menschenähnliche Antworten auf Texteingaben zu erzeugen. Es funktioniert, indem es mit großen Mengen von Textdaten trainiert und lernt, das nächste Wort in einer Abfolge anhand der vorherigen Wörter vorherzusagen.
ChatGPT kann zwar menschenähnliche Antworten generieren, hat aber auch seine Grenzen: Es generiert eventuell aufgrund der Daten, mithilfe derer es trainiert wurde, durch Bias verzerrte oder unangemessene Antworten. Dies ist ein häufiges Problem bei ML-Modellen, da sie eventuelle Verzerrungen und Einschränkungen der Trainingsdaten widerspiegeln. Wenn die Trainingsdaten beispielsweise eine Menge negativer Aussagen oder Beleidigungen enthalten, generiert ChatGPT möglicherweise Antworten, die ähnlich negativ oder beleidigend sind.
ChatGPT tut sich eventuell auch schwer damit, den Kontext der Benutzereingaben zu verstehen oder kohärente Antworten zu generieren. ChatGPT ist nur so gut wie die Daten, mit denen es trainiert wird. Wenn die Trainingsdaten unvollständig oder durch Bias verzerrt sind bzw. andere Fehler aufweisen, ist das Modell möglicherweise nicht in der Lage, genaue oder nützliche Antworten zu generieren. Dies kann bei Anwendungen, bei denen es auf Genauigkeit und Relevanz ankommt, eine erhebliche Einschränkung darstellen. Ähnlich wie bei anderen ML-Modellen spielen Daten eine entscheidende Rolle. Wenn die Trainingsdaten für das Modell schlecht sind, ist auch ChatGPT nicht sehr nützlich.
Der Beispiel ChatGPT zeigt, welche entscheidende Rolle Daten bei der effektiven Nutzung von KI spielen.
Datenlebenszyklus für KI
Der Datenlebenszyklus bezieht sich auf die Phasen, die Daten von der ersten Erfassung bis zu ihrer letztendlichen Löschung durchlaufen. Der Datenlebenszyklus für KI besteht aus einer Reihe von Schritten wie Datenerfassung, Vorverarbeitung, Training, Bewertung und Bereitstellung. Es ist wichtig sicherzustellen, dass die verwendeten Daten relevant, genau, vollständig und nicht durch Bias verzerrt sind und dass die erstellten Modelle effektiv und ethisch sind.
Der Datenlebenszyklus für KI ist ein laufender Prozess, da die Modelle kontinuierlich auf der Grundlage neuer Daten und Feedback aktualisiert und optimiert werden müssen. Dies ist ein iterativer Prozess, bei dem sorgfältig auf Details und die Verpflichtung für eine ethische und effektive KI geachtet werden muss. Entwickler und Benutzer von Modellen für maschinelles Lernen (ML) sollten sicherstellen, dass ihre Modelle effektiv, genau und ethisch sind und sich positiv auf die Welt auswirken. Der Datenlebenszyklus ist entscheidend, um sicherzustellen, dass Daten verantwortungsvoll und ethisch korrekt erfasst, gespeichert und verwendet werden.
Der Datenlebenszyklus umfasst folgende Phasen:
-
Datenerfassung: In dieser Phase werden Daten aus verschiedenen Quellen, wie Sensoren, Umfragen und Online-Quellen, gesammelt.
-
Datenspeicherung: Nach der Erfassung müssen die Daten sicher gespeichert werden.
-
Datenverarbeitung: In dieser Phase werden die Daten verarbeitet, um Erkenntnisse zu gewinnen und Muster zu erkennen. Dabei werden eventuell ML-Algorithmen oder andere Datenanalysetechniken eingesetzt.
-
Datennutzung: Wenn die Daten verarbeitet wurden, können sie für den geplanten Zweck verwendet werden, z. B. um Entscheidungen zu treffen oder Orientierungshilfen zu geben.
-
Datenfreigabe: Manchmal kann es notwendig sein, Daten mit anderen Unternehmen oder Personen zu teilen.
-
Datenaufbewahrung: Die Datenaufbewahrung bezieht sich darauf, wie lange die Daten gespeichert bleiben.
-
Datenvernichtung: Sobald die Daten nicht mehr benötigt werden, müssen sie sicher vernichtet werden. Hierzu werden digitale Daten sicher gelöscht oder physische Datenträger vernichtet.
KI und ML haben durchaus das Potenzial, viele Branchen zu revolutionieren und komplexe Probleme zu lösen. Es ist jedoch wichtig, dass wir uns ihrer Grenzen und der ethischen Aspekte bewusst sind. Fahren Sie mit der nächsten Lektion fort, um mehr über die Bedeutung von Datenethik und Datenschutz zu erfahren.
Ressourcen
- Externe Website: OneNine AI: KI-Anwendungsfälle nach Branche (auf Englisch)
- GitHub: Arten von Deep Learning-Modellen (in englischer Sprache)
- Trailhead: Künstliche Intelligenz – Grundlagen
- Blog Post: Wo liegen die Grenzen von ChatGPT? (in englischer Sprache)