Grundlegendes zu Datenbanken
Lernziele
Nachdem Sie diese Lektion abgeschlossen haben, sind Sie in der Lage, die folgenden Aufgaben auszuführen:
- Benennen von fünf Meilensteinen in der Geschichte von Datenbanken
- Unterscheiden zwischen relationalen und nicht-relationalen Datenbanken
- Definieren von "Big Data"
Die Geschichte der Datenbanken
"Die Daten sind in der Cloud." Diesen Satz hören wir immer wieder. Das Bild von Wasserdampf und Nebel, das durch diese Aussage heraufbeschworen wird, ist allerdings irreführend, denn tatsächlich handelt es sich ganz einfach um ein physisches Rechenzentrum voller Server. Salesforce verfügt über viele solcher Rechenzentren auf der ganzen Welt. Doch wie werden all diese Daten organisiert und wie kann darauf zugegriffen werden? Das hängt von der Datenbank ab. In dieser Einheit erhalten Sie einen Crashkurs zu den wichtigsten Datenbankkonzepten.
Zeitachse
Unsere Geschichte beginnt in den 1960er-Jahren, als ein Computer noch einen ganzen Raum füllte.
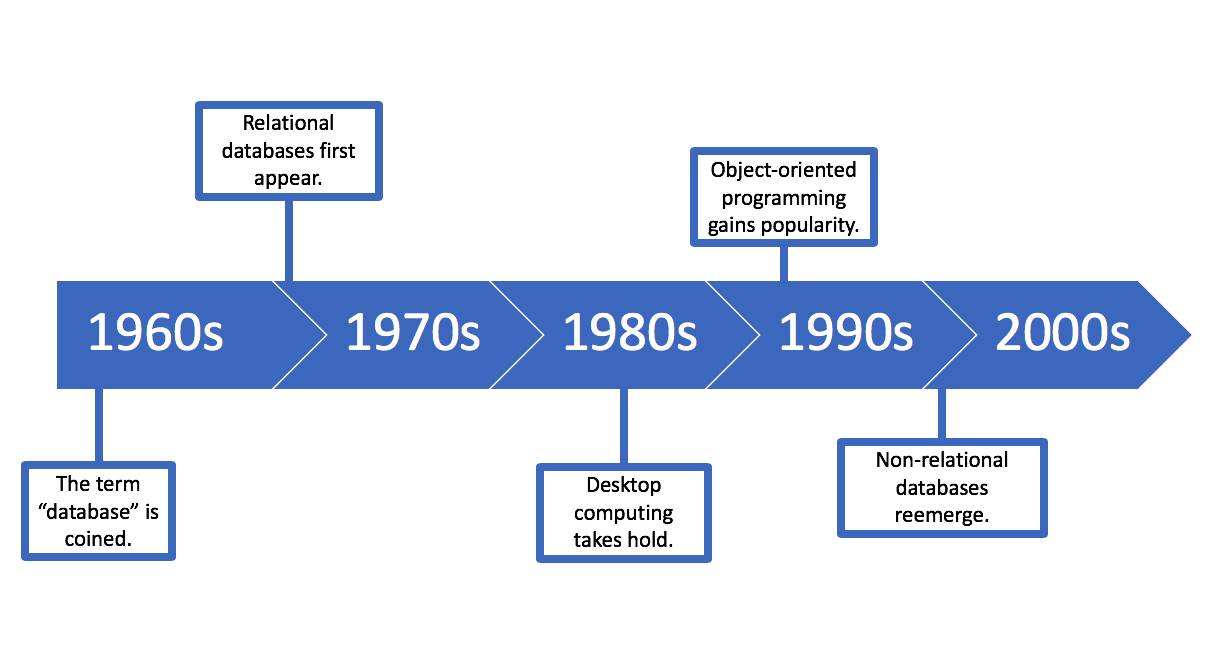
Jahrzehnt |
Meilensteine |
|---|---|
1960er |
Der Begriff "Datenbank" entstand Anfang der 1960er Jahre, als bandbasierte Speichermedien durch Plattenspeicher abgelöst wurden. Die ersten Datenbanken waren nicht-relational, d. h. sie verknüpften lediglich Listen von Freiform-Datensätzen. Das sollte sich innerhalb eines Jahrzehnts ändern. |
1970er |
In den 1970er-Jahren kamen relationale Datenbanken auf und wurden schließlich zur Norm. Im Gegensatz zu den vorherigen Datenbanken boten diese normalisierte, verwandte und durchsuchbare Tabellen. |
1980er |
Desktop-Computer wurden in den 1980er-Jahren allgemein verfügbar, ebenso wie benutzerfreundliche Unternehmenssoftware, die mit den zugrundeliegenden Datenbanken interagiert. |
1990er |
In den 1990er-Jahren ermöglichte die objektorientierte Programmierung (OOP) dann das Organisieren von Daten nach Klassen und Attributen anstelle von Tabellen und Feldern. |
2000er |
Nicht-relationale Datenbanken feierten in den 2000er-Jahren in Form von NoSQL (Not only SQL)-Datenbanken ein Comeback. Diese sind simpel und sehr gut skalierbar. Daher erfüllen sie die Anforderungen von Big Data und Echtzeit-Webanwendungen. |
Nach diesem kurzen geschichtlichen Abriss nehmen wird zwei wichtige Datenbankkategorien unter die Lupe.
Relational im Vergleich zu nicht-relational
Relationale Datenbanken beherrschten jahrzehntelang die Szene und sind auch heute noch von Bedeutung. Dabei werden Daten auf mehrere verwandte Tabellen aufgeteilt. Übergeordnete Tabellen beinhalten Zeilen mit eindeutigen Bezeichnern, genannt "Primärschlüssel". Untergeordnete Tabellen referenzieren diese Primärschlüssel mit anderen Bezeichnern ("Fremdschlüsseln"). Im Diagramm ist "Table A" die übergeordnete Tabelle und "Table B" die untergeordnete Tabelle.

Eigenschaften relationaler Datenbanken
Administratoren und Entwickler verwenden in der Regel SQL (Structured Query Language), um Daten in einer relationalen Datenbank zu bearbeiten oder darauf zuzugreifen. Transaktionen haben vier Eigenschaften, (die Sie sich über das Akronym ACID, im Deutschen auch AKID, gut merken können). Bei relationalen Datenbanken geht Konsistenz vor Verfügbarkeit.
- Atomic (Atomarität/Abgeschlossenheit): Alle Aufgaben müssen erfolgreich abgeschlossen werden, andernfalls wird die Transaktion per Rollback zurückgesetzt.
- Consistent (Konsistenz): Der Status der Datenbank muss während der gesamten Transaktion konsistent bleiben.
- Isolated (Isolation/Abgrenzung): Jede Transaktion ist isoliert und nicht von anderen abhängig.
- Durable (Dauerhaftigkeit): Daten aus einer fehlgeschlagenen Transaktion können wiederhergestellt werden.
Relationale Datenbanken sind ideal für komplexe Datenanalysen und Vorgänge. Sie weisen eine starre Struktur auf, in die die Daten passen müssen.
Allerdings lassen sich Daten manchmal einfach nicht in eine starre Struktur pressen. Diese Situation trat in den 1990er-Jahren ein, als das Internet immer stärker im Kommen war und Webanwendungen Daten generierten, die nicht ordentlich kategorisiert waren. Es folgte ein Wiederaufleben der nicht-relationalen Datenbanken, jetzt bisweilen auch "Not only SQL" (Nicht nur SQL)- oder "NoSQL"-Datenbanken genannt.
Typen nicht-relationaler Datenbanken

Es gibt vier Typen.
- Schlüssel-Wert-Paare basieren auf dem Modell assoziativer Datenfelder, d. h., die Daten werden in einer Sammlung von (Schlüssel+Wert)-Paaren dargestellt.
- Spaltenorientierte Datenspeicher weisen eine Tabellenstruktur auf. Die Spalten einer Tabelle können sich von Zeile zu Zeile ändern.
- Dokumentenorientierte Systeme speichern die Informationen jedes Dokuments als einzelne Instanz in der Datenbank. Dokumente können geschachtelt werden.
- Mit Graphen werden Elemente, die Beziehungen zwischen Elementen sowie Attribute, die zu Elementen und Beziehungen zugeordnet sind, organisiert.
Eigenschaften nicht-relationaler Datenbanken
Nicht-relationale Datenbanken haben drei Eigenschaften gemein. (Sie können sie sich mithilfe des Akronyms BASE gut merken.) Im Gegensatz zu relationalen Datenbanken geht bei nicht-relationalen Datenbanken Verfügbarkeit über Konsistenz.
- Basically available (grundsätzlich verfügbar): Das System ist verfügbar, selbst im Fall von Fehlern.
- Soft state (Übergangszustand): Der Zustand der Daten kann sich ändern.
- Eventual consistency (letztendlich konsistent): Konsistenz wird auf Transaktionsebene nicht gewährleistet, doch am Ende werden die Daten aller Knoten synchronisiert.
Nicht-relationale Datenbanken sind hochgradig skalierbar, da die Struktur einfach zu modellieren ist. Die Konsistenz kann unvollkommen sein, da es keine Garantie dafür gibt, dass alle Clients die gleichen Daten zur gleichen Zeit sehen.
Stellen wir die beiden Kategorien einmal gegenüber.
Relational |
Nicht-relational |
|---|---|
Normalisiert |
Denormalisiert |
SQL |
Begrenzte SQL oder asynchrone SQL |
Strukturierte Daten |
Strukturierte oder unstrukturierte Daten |
ACID-Transaktionen |
Keine oder begrenzte Transaktionen |
Es gibt keinen klaren Sieger, da jeder Datenbanktyp unterschiedliche Unternehmensanforderungen erfüllt. Wenn es um enorme Datenmengen geht, sind nicht-relationale Datenbanken der richtige Ansatz.
Wir begrüßen … Big Data
Klingt irgendwie beeindruckend, aber was ist das eigentlich? Big Data bezieht sich auf Datensets, die zu groß oder komplex sind, um von herkömmlicher Datenverarbeitungssoftware verarbeitet zu werden. Die Rede ist von Hunderten Millionen (oder gar Milliarden) Zeilen. Im Zeitalter von günstigem Speicher und schneller Verarbeitung sind wir überall mit Big Data konfrontiert. Künstliche Intelligenz (KI) nutzt maschinelles Lernen, um Datensätze schneller zu verarbeiten, als ein Mensch es je könnte.
Angesichts der preiswerten Angebote und der Schnelligkeit möchten die Unternehmen keinerlei Daten aufgeben. Doch wie sollen sie sich zwischen nicht-relationalen Datenbanken (zur Bewältigung der enormen Mengen unterschiedlichster Daten) und relationalen Datenbanken (für die Abwicklung komplexer Geschäftslogik) entscheiden? Tatsächlich ist eine Unternehmensarchitektur erforderlich, um alle Aufgaben zu bewältigen. Mehrere Technologien müssen in eine umfassende Lösung integriert werden.
Nachdem Sie sich ein wenig mit Datenbanken und den mit Big Data verbundenen Herausforderungen vertraut gemacht haben, werden wir in der nächsten Einheit herausfinden, wie Salesforce für die Datenspeicherung verwendet werden kann.