Verwandeln von Daten in Modelle
Lernziele
Nachdem Sie diese Lektion abgeschlossen haben, sind Sie in der Lage, die folgenden Aufgaben auszuführen:
- Erläutern der Unterschiede zwischen manuell programmierten Algorithmen und trainierten Modellen
- Definieren von maschinellem Lernen und seiner Beziehung zu KI
- Unterscheiden zwischen strukturierten und unstrukturierten Daten und ihrer Auswirkung beim Trainieren von Modellen
Trailcast
Wenn Sie sich eine Audioaufzeichnung diesem Modul anhören möchten, nutzen Sie den nachstehenden Player. Denken Sie nach dem Anhören dieser Aufzeichnung daran, zur jeweiligen Lektion zurückzukehren, sich die Ressourcen anzusehen und die zugehörigen Aufgaben zu absolvieren.
Blick hinter die Kulissen der Magie
Was KI leisten kann, mag wie Magie erscheinen. Und wie bei der Magie möchte man natürlich gerne einen Blick hinter den Vorhang werfen, um zu sehen, wie das alles funktioniert. Sie werden feststellen, dass Informatiker und Wissenschaftler anstelle von Spiegeln und Ablenkungsmanövern eine Menge Daten, Mathematik und Rechenleistung einsetzen. Wenn Sie wissen, wie KI tatsächlich funktioniert, können Sie ihr Potenzial optimal ausschöpfen und gleichzeitig die Fallstricke vermeiden, die sich aus ihren Grenzen ergeben.
Der Wechsel von manuellem Programmieren zu Trainieren
Seit Jahrzehnten schreiben Programmierer Code, der eine Eingabe akzeptiert, sie anhand einer Reihe von Regeln verarbeitet und eine Ausgabe zurückgibt. So lässt sich zum Beispiel der Durchschnitt aus einer Reihe von Zahlen ermitteln:
- Eingabe: 5, 8, 2, 9
- Verarbeitung: Addiere die Werte [5 + 8 + 2 + 9] und dividiere die Summe durch die Zahl der Eingaben [4]
- Ausgabe: 6
Dieser einfache Regelsatz zur Umwandlung einer Eingabe in eine Ausgabe ist ein Beispiel für einen Algorithmus. Es wurden schon Algorithmen für ziemlich anspruchsvolle Aufgaben geschrieben. Doch bei manchen Aufgaben gibt es so viele Regeln (und Ausnahmen), dass es unmöglich ist, sie alle in einem handgeschriebenen Algorithmus unterzubringen. Schwimmen ist ein gutes Beispiel für eine Aufgabe, die sich nur schwer in eine Reihe von Regeln packen lässt. Man bekommt vielleicht ein paar Ratschläge, bevor man in das Schwimmbecken springt, aber man findet erst dann wirklich heraus, was funktioniert, wenn man den Kopf über Wasser zu halten versucht. Manche Dinge lernt man am besten durch Erfahrung.
Wie wäre es, wenn wir einen Computer auf dieselbe Weise trainieren könnten? Natürlich nicht, indem man ihn in ein Schwimmbecken wirft, sondern indem man ihn herausfinden lässt, was funktioniert, um eine Aufgabe erfolgreich zu bewältigen. Doch genauso wie das Schwimmenlernen sich deutlich vom Erlernen einer Fremdsprache unterscheidet, hängt auch die Art des Trainings von der Aufgabe ab. Sehen wir uns einige der Möglichkeiten für das Trainieren von KI an.
Erfahrung sammeln
Stellen Sie sich vor, Sie halten jedes Mal, wenn Sie Milch kaufen gehen, die Details dazu in einer Tabelle fest. Das klingt zwar etwas seltsam, machen Sie aber bitte einfach mit. Sie richten die folgenden Spalten ein:
- Einkauf am Wochenende?
- Uhrzeit
- Regnet es?
- Entfernung zum Laden
- Gesamtdauer für den Einkauf
Nach mehreren Einkäufen bekommen Sie ein Gefühl dafür, wie sich die Bedingungen auf die Dauer auswirken. Wenn es zum Beispiel regnet, dauert der Einkauf länger, doch gleichzeitig sind weniger Leute beim Einkaufen. Ihr Gehirn stellt Verbindungen zwischen den Eingaben (Wochenende [W], Zeit [T], Regen [R], Entfernung [D]) und der Ausgabe (Minuten [M]) her.
Doch wie bringen wir einen Computer dazu, Trends bei Daten erkennen und einschätzen zu können? Eine Möglichkeit ist die Guess-and-Check-Methode. Das geht so:
Schritt 1: Weisen Sie allen Ihren Eingaben eine "Gewichtung" zu. Dies ist eine Zahl, die angibt, wie stark sich eine Eingabe auf die Ausgabe auswirken soll. Es ist völlig in Ordnung, wenn Sie zu Anfang dieselbe Gewichtung für alle Eingaben festlegen.
Schritt 2: Verwenden Sie die Gewichtungen zusammen mit Ihren vorhandenen Daten (und einigen cleveren mathematischen Formeln, auf die wir hier nicht näher eingehen), um die Minuten für einen Milcheinkauf zu schätzen. Wir können die Schätzung mit den historischen Daten vergleichen. Sie wird weit daneben liegen, aber das macht nichts.
Schritt 3: Lassen Sie den Computer für jede Eingabe eine neue Gewichtung schätzen, so dass manche etwas wichtiger sind als andere. Die Tageszeit könnte beispielsweise wichtiger sein als die Frage, ob es regnet.
Schritt 4: Führen Sie die Berechnungen erneut durch, um zu prüfen, ob die neuen Gewichtungen eine bessere Schätzung ergeben. Fall ja, bedeutet dies, dass die Gewichtungen besser passen und in die richtige Richtung geändert wurden.
Schritt 5: Wiederholen Sie die Schritte 3 und 4, und lassen Sie den Computer die Gewichtungen so lange optimieren, bis seine Schätzungen nicht mehr besser werden.
An diesem Punkt hat der Computer die Gewichtungen für die einzelnen Eingaben festgelegt. Wenn Sie sich unter Gewichtung vorstellen, wie stark eine Eingabe mit der Ausgabe verbunden ist, können Sie ein Diagramm erstellen, in dem die Gewichtung durch die Linienstärke dargestellt wird.
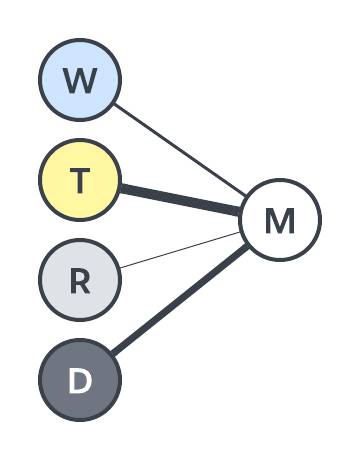
In unserem Beispiel scheint die Tageszeit den stärksten Einfluss zu haben, während sich Regen nicht sehr auszuwirken scheint.
Mit diesem Guess-and-Check-Prozess haben wir ein Modell unserer Milcheinkäufe erstellt. Und wie ein Modellboot können wir es mit ans Wasser nehmen, um zu sehen, ob es schwimmt. Das heißt, wir testen es in der realen Welt. Lassen Sie also vor Ihrem nächsten Milcheinkauf das Modell abschätzen, wie lange sie brauchen werden. Wenn das Modell häufig genug richtig liegt, können Sie die Schätzung für alle weiteren Einkäufe getrost dem Modell überlassen.

[In DreamStudio mit KI-generiertes Bild stability.ai. Die Aufforderung lautete "Ein Roboter baut an einem Tisch die Teile eines kleinen Modellsegelboots zusammen. Das Bild wird im Stil einer 2D-Vektorgrafik gezeichnet."]
Verwenden der passenden Daten für die passende Aufgabe
Dies ist zwar ein sehr einfaches Beispiel dafür, wie durch Trainieren ein KI-Modell erstellt werden kann, doch es reißt trotzdem einige wichtige Ideen an. Erstens ist es ein Beispiel für maschinelles Lernen (ML), also der Prozess, bei dem große Datenmengen verwendet werden, um ein Modell für Vorhersagen zu trainieren, anstatt einen Algorithmus von Hand zu programmieren.
Zweitens zeigt sich hier, dass nicht alle Daten gleich sind. In unserem Beispiel zum Milcheinkauf handelt es sich bei der Kalkulationstabelle um so genannte strukturierte Daten. Die Daten sind gut organisiert, und jede Spalte ist beschriftet, damit Sie die Bedeutung jeder Zelle kennen. Im Gegensatz dazu wären unstrukturierte Daten beispielsweise so etwas wie ein Zeitungsartikel oder eine unbeschriftete Bilddatei. Die Art der verfügbaren Daten wirkt sich auf die Art des Trainings aus, das Sie durchführen können.
Drittens ermöglichen die strukturierten Daten aus unserer Tabelle Computern ein beaufsichtigtes Lernen. Man spricht von beaufsichtigtem Lernen, da wir sicherstellen können, dass es zu jedem einzelnen Eingabedatenpunkt eine passende, erwartete Ausgabe gibt, die wir überprüfen können. Im Gegensatz dazu werden unstrukturierte Daten für nicht beaufsichtigtes Lernen verwendet, bei dem die KI versucht, Verbindungen in den Daten zu finden, ohne wirklich zu wissen, wonach sie sucht.
Es ist nur eine Trainingsmöglichkeit, den Computer für jede Eingabe eine Gewichtung herausfinden zu lassen. Doch oft sind vernetzte Systeme komplizierter, und eine 1:1-Gewichtung kann die Lage klarer abbilden. Wie Sie in der nächsten Einheit sehen werden, gibt es glücklicherweise noch andere Möglichkeiten des Trainings!