Augment Agents and Prompts with Relevant Business Knowledge
Learning Objectives
After completing this unit, you’ll be able to:
- Explain why retrieval augmented generation (RAG) improves the accuracy and relevance of LLM responses in agents and prompt templates.
- Describe how to set up and use RAG in your Salesforce org.
What Is Retrieval Augmented Generation?
Retrieval augmented generation (RAG) is a popular way to ground prompt requests to large language models (LLMs). Grounding adds domain-specific knowledge or customer information to the prompt, giving the LLM context to respond more accurately to a question or task.
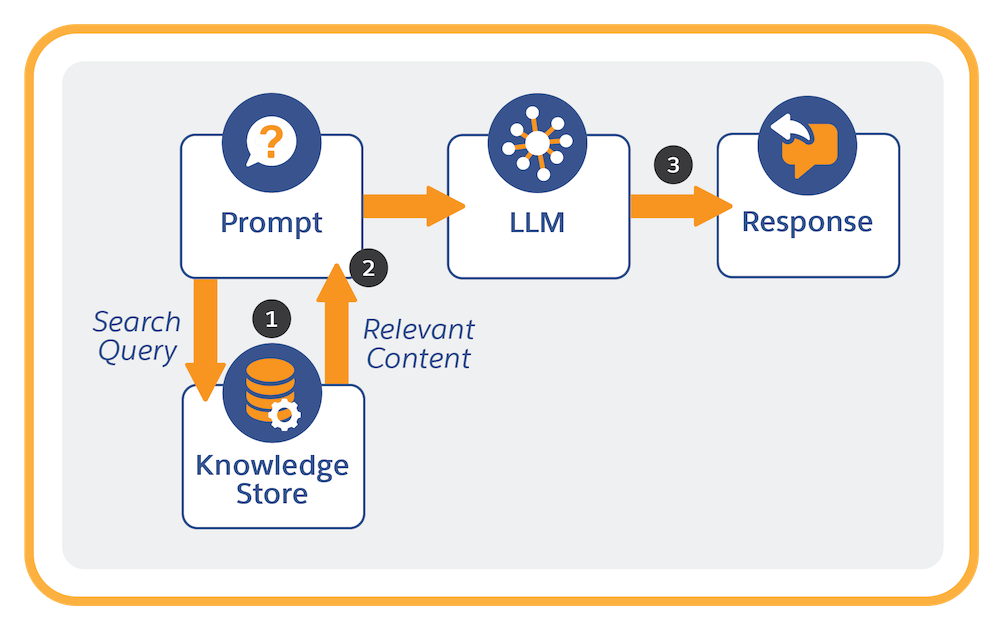
To break it down, RAG:
-
Retrieves relevant information from a knowledge store containing structured and unstructured content.
-
Augments the prompt by combining this information with the original prompt.
- With the augmented prompt, the LLM generates a response.
Many LLMs are trained generally across the Internet on static and publicly available content. RAG adds domain-specific information to help LLMs give you better responses to your prompts. With RAG, you can extract valuable information from all sorts of content, such as service replies, cases, knowledge articles, conversation transcripts, RFP (request for proposal) responses, emails, meeting notes, frequently asked questions (FAQs), and more.
Quick-Start Agentforce Solutions With Agentforce Builder and Agentforce Data Library
Agentforce Builder allows you to seamlessly choose knowledge articles or upload files for retrieval by agents with just a few clicks. You can do this by selecting or creating an Agentforce Data Library, which is a library of content the agent uses to answer questions. Select the source from which the data library pulls relevant information: Salesforce Knowledge base, files that you upload (text, HTML, and PDFs), or a web search. At run time, your agent uses this information to ground LLM prompts and produce better, more accurate, and relevant LLM responses.
When you add a data library, you automatically create all the elements needed for a working, RAG-powered solution. If you want, you can then customize these elements to fine-tune RAG solutions for your use cases. We’ll get to that later.
Get Relevant Business Knowledge in Agents
Agents get relevant knowledge from a data library using the Answer Questions with Knowledge standard action. This action dynamically retrieves from the knowledge or file content you specified when you created or selected a library.
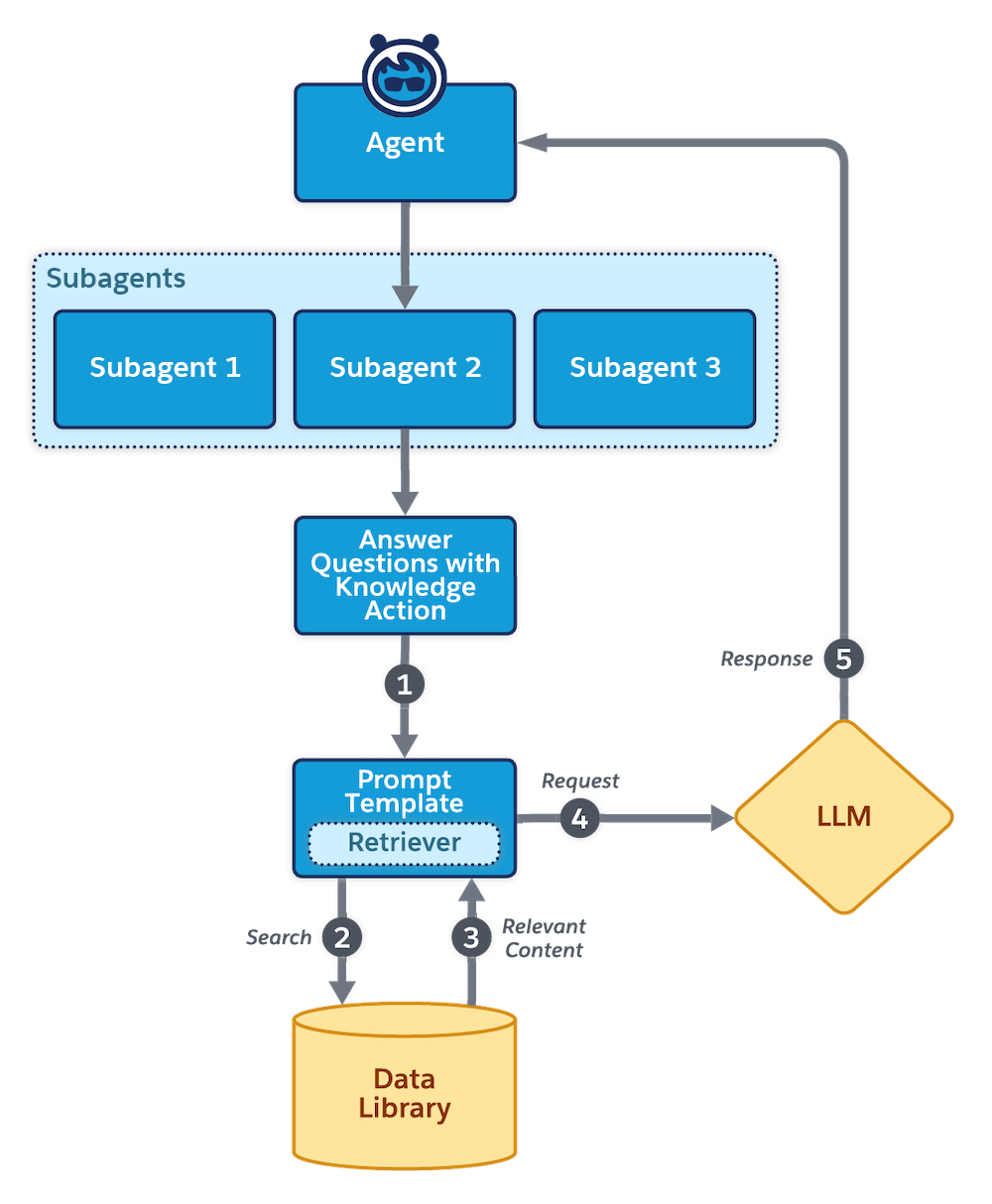
Each time the Answer Questions with Knowledge action is run:
- The action runs the associated prompt template. The retriever is invoked with a dynamic query.
- The query searches the data library.
- The query retrieves the relevant content.
- The original prompt is populated with information retrieved from the data library, and then submitted to the LLM.
- The LLM-generated response is forwarded to the agent.
Get Relevant Business Knowledge in Prompts
At run time, prompt templates pull relevant information from your data library to ground LLM prompts that result in more accurate LLM responses. If you’re using a custom prompt template, in Prompt Builder, simply embed a retriever that you select when inserting a resource. You can also use a custom retriever that fine-tunes search settings for any given prompt.
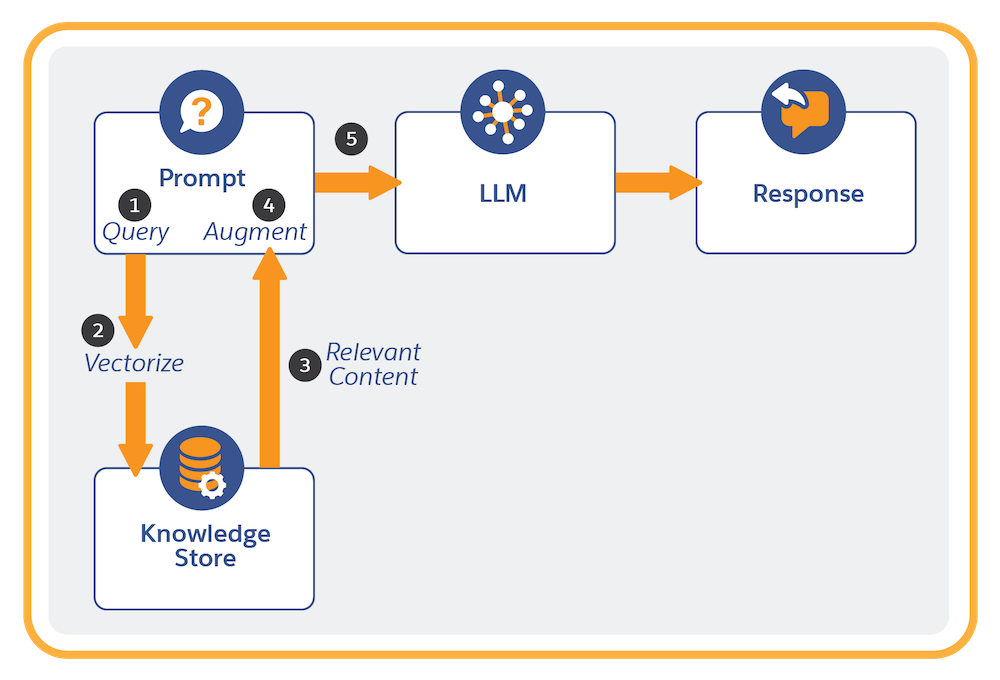
Each time a prompt template with a retriever is run:
- The retriever is invoked with a dynamic query that’s initiated from the prompt template.
- The query is vectorized (converted to numeric representations). Vectorization enables search to find semantic matches in the search index (which is already vectorized).
- The query retrieves the relevant content from the indexed data in the search index.
- The original prompt is populated with the information retrieved from the search index.
- The prompt is submitted to the LLM, which generates and returns the prompt response.
Advanced Customization in Data 360
When you add a data library, either in Agentforce Builder or from Setup, Salesforce automatically builds a RAG-powered solution using default settings for all of the components: vector data store, search index, retriever, prompt template, and standard action. You can set up and customize these components individually.
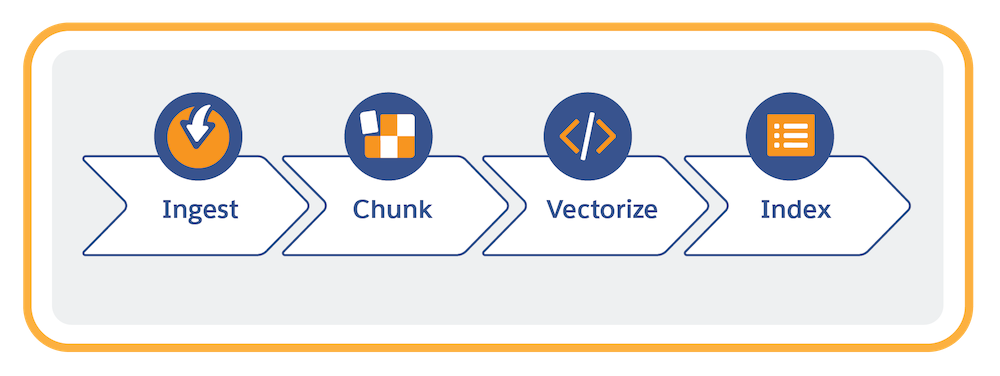
Data preparation involves these tasks in Data 360.
- Connect (ingest) your unstructured data.
- Create a search index configuration that chunks and vectorizes the content. Data 360 uses a search index to manage structured and unstructured content in a search-optimized way. You have two search options: vector search and hybrid search. Hybrid search combines vector + keyword search.
- Chunking breaks the text into smaller units, reflecting passages of the original content, such as sentences or paragraphs.
- Vectorization converts chunks into numeric representations of the text that capture semantic similarities.
- Chunking breaks the text into smaller units, reflecting passages of the original content, such as sentences or paragraphs.
- Store and manage the search index.
After a search index is created, create a retriever in AI Models (formerly Einstein Studio) to fetch relevant information from that search index for a specific use case. A retriever is a resource that you embed in a prompt template to search for, and return, relevant information from the knowledge store. To support a variety of use cases, you can create different retrievers that focus your search on just the relevant subset of information to add to the prompt. For a hands-on experience, take the Advanced RAG with Data 360 and Agentforce module.
See RAG in Action
This video shows how easy it is to augment a prompt template using RAG.
Conclusion
Agentforce Data Library and RAG in Data 360 are integrated with the Einstein generative AI platform. Natively incorporate RAG functionality into out-of-the-box apps like Agentforce Builder and Prompt Builder. With RAG, you can safely ground and improve your Agentforce solutions with proprietary data from a harmonized data model.
Resources
- Salesforce Help: Unstructured Data in Data 360
- Salesforce Help: Data 360—Chunk and Vectorize Data
- Salesforce Help: Data 360—Vector Search
- Salesforce Help: Data 360—Hybrid Search
- Salesforce Help: Example: Agentic RAG with Advanced Data 360 Setup
- Trailhead: Agentforce Data Library Basics
- Trailhead: Unstructured Data in Data 360
- Trailhead: Search Index Types in Data 360: Quick Look
- Trailhead: Hybrid Search for RAG: Quick Look
- Salesforce Blog: RAG – The Hottest 3 Letters in Generative AI Right Now
- Salesforce Blog: Agentforce and RAG: Best Practices for Better Agents