Perform Data Transformation with Nodes
Learning Objectives
After completing this unit, you’ll be able to:
- List the types of Data Processing Engine nodes.
- Describe the uses of each node.
- Describe input variables.
Swap Code with Nodes
Data Processing Engine provides a visual definition builder tool that you can use to capture the multistep data transformation process using data sources and nodes.

Transformations typically require complex code, however, Data Processing Engine uses nodes to transform data in a much easier and simpler way. Whether you want to join two datasets, calculate a field value, or append a dataset to another dataset, there are different nodes available for each of these functions. When you create a definition, click New Node in the definition builder canvas to start adding nodes. The first node by default is always a Data Source node. Here’s the New Node window showing different node types.

Next, review each of these nodes in detail.
Data Source
To transform data, you direct Data Processing Engine where to extract data from. You define source objects using the Data Source node and select its fields as data sources. For example, if the Contract object is the source, you can select all the Contract fields. Additionally, you can also select objects related to the Contract object, such as Account and Owner objects, and the fields related to these objects.
All the related objects have a lookup relationship with the primary data source object. For related object fields, specify a unique alias so you can easily reference them in subsequent nodes.
Join
A Join node combines rows from two nodes based on one or more related fields between them. From the records of the two nodes, select the fields that you want as part of the output, and map fields with the same data type.
There are four types of joins you can choose from: Left Outer, Right Outer, Outer, and Inner. Learn about each Join node type through an example.
First, consider the Order node with sample fields and records.
Order ID |
Account Name |
Order Date |
|---|---|---|
10101 |
Ursa Major Solar |
5/5/2024 |
10102 |
Bloomington Caregivers |
7/1/2024 |
10105 |
Cloud Kicks |
6/12/2024 |
Similarly, examine the Order Product node.
Order ID |
Product Name |
Product Code |
|---|---|---|
10101 |
Cloud One |
CO1234 |
10102 |
Cloud Two |
CO1235 |
10106 |
Cloud Four |
CO1237 |
Inner Join
Use a Join node with Inner Join node type and add the Order node and Order Product node as first and second source nodes. Use the Order ID field to join the two nodes as it’s the related field between the nodes. Select Order ID, Product Name, and Order Date fields from the respective nodes to use them as part of the output. The Inner Join node returns all the records for the selected fields that have matching Order IDs in both the nodes. Here’s how the Inner Join output looks like.
Order ID |
Product Name |
Order Date |
|---|---|---|
10101 |
Cloud One |
5/5/2024 |
10102 |
Cloud Two |
7/1/2024 |
Left Outer Join
A Left Outer Join node returns all the records for the selected fields from the first source node and matching records from the second source node. A Left Outer Join node returns all records from the first source node even if there are no matches in the second source node. In our example, use the Left Outer Join type and select the Order ID field from the first and second node. Select the Account Name and Product Code fields from the first node and second node respectively. Join the two nodes using the Order ID field. Here’s how the Left Outer Join output looks like.
Order ID |
Account Name |
Product Code |
|---|---|---|
10101 |
Ursa Major Solar |
CO1234 |
10102 |
Bloomington Caregivers |
CO1235 |
10105 |
Cloud Kicks |
Right Outer Join
A Right Outer Join node returns all the records for the selected fields from the second source node and matching records from the first source node. A Right Outer Join node returns all records from the second source node even if there are no matches in the first source node. In our example, use the Right Outer Join type and select the Order ID field from the first and second node. Select the Account Name and Product Name fields from the first and second node respectively. Join the two nodes using the Order ID field. Here’s how the Right Outer Join output looks like.
Order ID |
Account Name |
Product Name |
|---|---|---|
10101 |
Ursa Major Solar |
Cloud One |
10102 |
Bloomington Caregivers |
Cloud Two |
10106 |
Cloud Four |
Outer Join
An Outer Join node returns all the records and fields from the first and second source nodes.
Order ID |
Account Name |
Order Date |
Product Name |
Product Code |
|---|---|---|---|---|
10101 |
Ursa Major Solar |
5/5/2024 |
Cloud One |
CO1234 |
10102 |
Bloomington Caregivers |
7/1/2024 |
Cloud Two |
CO1235 |
10105 |
Cloud Kicks |
6/12/2024 |
||
10106 |
Cloud Four |
CO1237 |
Filter
In an object or dataset, you likely have a lot of unwanted data to shift through. Adding filter conditions helps you refine that data and you can fetch the specific data from the order or dataset. Define filter conditions using the Filter node by either specifying a value or using an input variable. Here’s the Filter Order node configuration pane showing the source node and filter conditions.

For example, if you need all the orders from the start of the current financial year till date, add a filter node with the Order object as the source node. Then add a condition where the order Effective Date is greater than or equal to the start date. The Filter node fetches only those orders that match the condition.
Append
The Append node merges two or more nodes with matching structures. For example, if you have sales data from two regions—North and South—and both nodes have the same fields, such as Salesperson, Sale Amount, and Date, and field types. By appending them, you create a unified dataset that includes sales data from both regions, resulting in comprehensive analysis across regions.
Group and Aggregate
The Group and Aggregate node groups fields based on specific field types, such as Text, Date, Date or Time. You can then perform aggregations like sums, averages, or counts on other fields. For example, you can group sales records by Salesperson and calculate the total Sale Amount for each sales agent. This helps summarize large datasets, offering insights into key metrics by grouping and calculating aggregated data.
Formula
Create multiple formulas and store the results of each formula in a new field. Before you create a formula, specify the alias, data type, and format of the derived field. The derived field can be of various data types, such as Date, Date or Time, Numeric, and Text. For example, the formula to uniquely identify every employee with the department they belong to is CONCAT({FirstName}, {LastName},{Department}). The formula field must be of the type Text.

Hierarchy
Determine a field’s hierarchy path based on the parent field you select. The Hierarchy node only provides the hierarchy path, not the field value that’s stored at every hierarchy level. For example, if you have an organizational hierarchy where each employee reports to a manager, the Hierarchy node helps outline the reporting structure without displaying the specific employee or manager data at each level.
Slice
When you create a Data Processing Engine definition, sometimes you no longer require certain fields for processing. In such a case, use the Slice node to select the fields you want to keep and the remaining fields are automatically dropped from the dataset. The dropped fields aren't removed from the source node though. This helps simplify the dataset for the next steps while leaving the original data unchanged. For example, if your dataset includes the fields Customer Name, Order ID, and Order Date, but you only need the first two, use the Slice node to keep those fields and drop the rest.
Forecast
The Forecast node predicts patterns for specific time periods in the future using today’s data. The node analyzes the past data points and their corresponding dates from the source data that you define in the Data Processing Engine definition. The node then predicts future values based on historical data. For example, you can estimate the order quantity for the next four quarters based on the orders placed in the past 5 years.
Writeback Object
After you transform the data, load it into an object within your org. Use the Writeback Object node to create, update, or upsert records with the transformed data to a target object.
Here’s the Get Order Aggregate Data Processing Engine definition builder page showing the configured nodes.
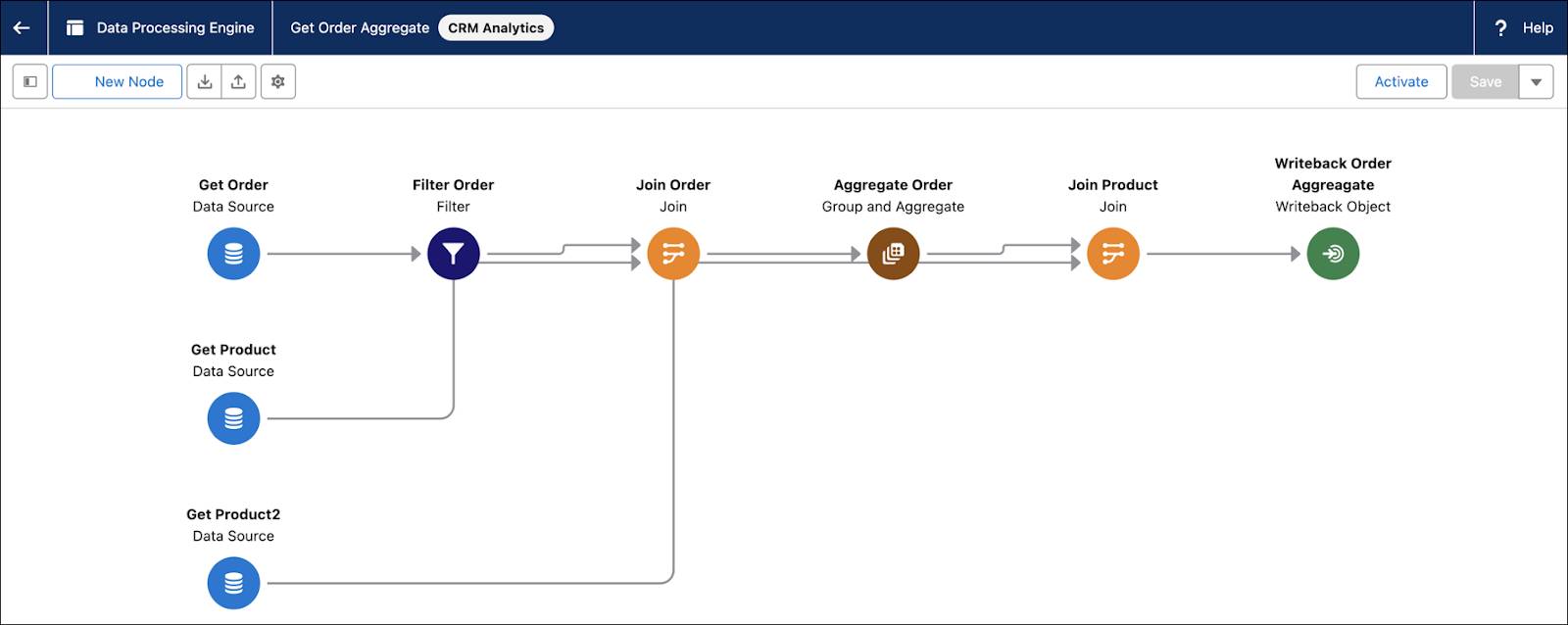
Except for the Data Source node, each node you add in the definition must have a source node or connected to a previous node.
Composite Writeback
The Composite Writeback node consolidates related records from one or more writeback object nodes together in a single, coordinated transaction. A standard Writeback Object node writes data to one object. A Composite Writeback node can write data to many objects that have related records, like an Account and its Contacts. It acts as a parent container for multiple individual Writeback Object nodes. The Composite Writeback node ensures data integrity.
Input Variables
An input variable stores data that you can refer to at different points in the Data Processing Engine definition. You can use input variables in Data Source, Filter, and Formula nodes. If a field value is likely to change during a Data Processing Engine definition run, create an input variable for it and either provide a value or leave it blank. When you run the definition, you can dynamically define or change the input variable value. This reduces effort and eliminates the risk of manually changing every instance of the value in the definition.
Consider a scenario where you have a definition that processes sales data and you must filter records based on a specific date range. Instead of hard-coding the date range in multiple places, create input variables for the start and end dates. When you run the definition, you can easily update the date values as needed. The image here shows the Input Variables tab where you can add input variables such as Date.

An input variable can be text, number, expression, file identifier, date, date and time, or filter. For a Filter type variable, enter a valid JSON syntax.
Wrap Up
In this module, you learned what Data Processing Engine is and how it helps Salesforce Industries to transform data and resolve their existing limitations. You explored the design-time and run-time process workflows. You also got an overview of each Data Processing Engine node. You're now ready to set up your Data Processing Engine definitions and execute them as per your business needs.