Get to Know Data Processing Engine
Learning Objectives
After completing this unit, you’ll be able to:
- Define Data Processing Engine.
- Describe the challenges faced by Salesforce Industries.
- Describe the capabilities of Data Processing Engine.
- Explain how Data Processing Engine works.
- Describe how Salesforce Industries use Data Processing Engine.
Power of Data
This is the era of digital economy. Data has become the key component for the proper functioning of everything from governments to private businesses. In a business, marketing departments use data to narrow down their customer segments, sales departments rely on data to understand their customers’ needs, and business executives study market trends to tailor their strategies. Data drives every aspect of a business.
But with the vast amounts of data available from different sources, how do you transform all that data into actionable business intelligence? That’s where Data Processing Engine comes in. Data Processing Engine orchestrates transformations of large volumes of customer data for any industry.
Challenges Faced by Salesforce Industries
Multiple Salesforce Industry Clouds faced these challenges with processing and transforming large volumes of data.
- Handling large volumes of data in the core system posed a significant technical challenge.
- Platform limitations affected memory-intensive tasks. For example, in Agentforce Financial Services, the Rollup by Lookup feature could only process 2000 records per batch. The processing time was limited by system resources, workflows, concurrent processes, CPU, and heap size.
- There was no easy way to create customizable data transformations, such as multi-step joins, filters, and computations from multiple data sources.
Key Capabilities of Data Processing Engine
Data Processing Engine is a core service that orchestrates data transformations at scale. Data Processing Engine provides capabilities that help customers overcome current challenges. Here’s how.
-
Metadata-driven visual tool: Data Processing Engine provides a visual tool that uses metadata to configure nodes and transform data.
-
Multiple data sources: Data Processing Engine uses objects in core, Data 360 objects or datasets from CRM Analytics as data sources.
-
High-volume data transformation: Data Processing Engine provides high-volume data calculation and aggregation services. Data Processing Engine uses CRM Analytics or Data 360 platform to provide scale and performance.
-
Writeback capability: Data Processing Engine provides the ability to write data back to objects. Data Processing Engine stores the transformed data in Salesforce objects in core, datasets in CRM Analytics, or Data 360 objects.
-
Input variables in run time: Data Processing Engine helps you to declare specific input variables during run time. These variables or inputs are provided when you initiate the Data Processing Engine run. You can also define default values if required.
-
No-code data transformations: Data Processing Engine transforms data without coding by using nodes such as join, filter, formula, writeback object, group and aggregate, and many others.
-
API support: Data Processing Engine provides APIs to set up, activate, and invoke the Data Processing Engine process.
How Data Processing Engine Works
Data Processing Engine, at a high level, helps transform business data in three steps as shown here.

-
Define data sources: Consider that you have to integrate data from different objects. First, decide what data to extract from which objects. Then define the data sources and extract the data. At this point, the data is not relevant to your purpose. You must transform it into something you can work with.
-
Define data transformations: Based on what you’re looking to get out of the data, define the sequence of steps to transform the data. You can join, filter, group, and aggregate various fields and objects in Data Processing Engine.
-
Execute data transformations: After you’ve added the transformation steps, execute the steps to perform data transformations.
What happens to the transformed data? Data Processing Engine loads or writes back the transformed data to a destination or target object as new or updated data.
By automating the process of manual, code-driven data integration, Data Processing Engine improves efficiency and productivity, and also eliminates error probability.
Now, dive deeper into Data Processing Engine and learn about the design-time and run-time processes.
Explore Data Processing Engine Design-Time Workflow
In the Data Processing Engine design-time process, you set up the definition and data sources as per your requirement. Review this design-time process workflow and learn about the tasks involved.

When using Data Processing Engine, the first step is to create a Data Processing Engine definition. The definition is like a container for your configuration that defines how to transform your source data and where you want to store the results. Next, you define the data sources in the definition from where you extract the data. Data Processing Engine supports Salesforce core objects, Data 360 objects, or datasets in CRM Analytics as data sources. Then, you add nodes to define how the data must be transformed. The data transformation depends on the run-time platform and nodes you choose to run this definition.
Data Processing Engine supports two run-time platforms: Data 360 and CRM Analytics. These are high-performance data platforms that clean, transform, and enrich large volumes of data at scale. After you define the transformation, you then define the target object and fields where the result is stored. This process is called writeback. You can write back the results in multiple entities within the same definition.
After completing the definition setup, activate and run the definition to use it. You can monitor the definition run process using the Monitor Workflow Services feature. Use this feature to view the status of a Data Processing Engine definition's run and its individual tasks. You can also run this definition using a Flow or Apex.
Explore Data Processing Engine Run-Time Workflow
After you finish configuring your definition and nodes during design time, run the definition. The data extraction, transformation, and writeback process happens during run time. As shown here, Data Processing Engine run time process consists of three steps: Data Sync, Data Transformation, and Writeback Results.
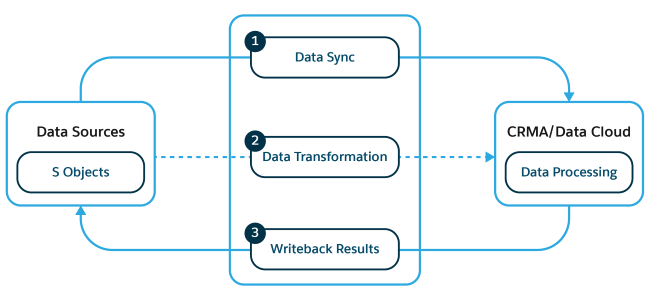
-
Data Sync (1): When you run a Data Processing Engine definition, a batch job record is automatically created and data is synced from the data sources as defined in the definition to the run-time platform. The data sources can be Salesforce core objects, Data 360 objects, or datasets in CRM Analytics.
-
Data Transformation (2): The batch job executes all the nodes of the definition, transforms the data, and sends the data back to Data Processing Engine. The Data Processing Engine run-time process uses platforms like CRM Analytics or Data 360 to execute these transformations.
-
Writeback Results (3): After executing the definition successfully, Data Processing Engine writes back the transformed data to the defined target entities.
How Salesforce Industries Use Data Processing Engine
Check out these use cases to learn how various Salesforce Industry products use Data Processing Engine to enhance their business processes and perform large-scale data transformations with ease.
Salesforce Industry Products |
Data Processing Engine Use Cases |
|---|---|
Agentforce Financial Services |
For Agentforce Financial Services, Data Processing Engine:
|
Loyalty Management |
For Loyalty Management, Data Processing Engine:
|
Rebate Management |
For Rebate Management, Data Processing Engine:
|
Manufacturing |
For Manufacturing, Data Processing Engine:
|
What’s Next
In this unit, you learned about Data Processing Engine and how it helps transform large volumes of data across industries. You got to know the Data Processing Engine design-time and run-time workflows. You also learned about the challenges Salesforce Industry Clouds faced and how Data Processing Engine resolves them. In the next unit, explore the various Data Processing Engine nodes and input variables.