Explore Foundation Models in Amazon Bedrock
Learning Objectives
After completing this unit, you’ll be able to:
- Differentiate between base, custom, and imported foundation models in Amazon Bedrock.
- Explain how model parameters improve model performance and output quality.
- Apply best practices when working with foundation models.

Before You Start
Before you start this module, make sure you complete the Amazon Bedrock badge on Trailhead. The work you do here builds on the concepts and work you do in that badge.
Foundation Models
Foundation models (FM) are artificial intelligence (AI) models that have a vast amount of parameters and are trained on a number of different unlabeled data, such as text from the internet, images, or code. The intention is that when you apply these models to generative AI applications, you can generate a variety of responses that are accurate and consistent.
Models Amazon Bedrock Supports
Amazon Bedrock provides a broad choice of FMs from leading AI companies such as AI21 Labs, Amazon, Anthropic, Cohere, Meta, Stability AI, and Mistral AI. FMs can be used as-is (base models) or further fine-tuned through additional training.
One important feature of foundation models is their self-supervised learning ability. This means the models can learn patterns and relationships from raw data without human-labeled examples, creating their own understanding of the content. This capability lets the models generate images, video, audio, and text.
In Amazon Bedrock, you can access the model that has been trained on specific datasets and optimized for particular use cases. Let’s explore the capabilities of the models provided by leading companies.
-
AI21 Labs: FMs that specialize in enterprise-focused tasks like text generation, question answering, summarization, and so on.
-
Amazon: Models that can take care of various tasks from text and image generation to summarization, classification, information extraction, and open-ended Q&A.
-
Anthropic: FMs that are built with Constitutional AI principles and excel in reasoning tasks, creative writing, thoughtful dialogue, and coding.
-
Cohere: FMs that are effective for generating content, creating summaries, and implementing Retrieval-Augmented Generation (RAG) applications. They also offer capabilities for searching through and classifying large volumes of text.
-
Meta: FMs that focus on natural dialogue and language understanding. They perform well in conversational situations, question-answering tasks, and reading comprehension challenges.
-
Stability AI: FMs that focus on creating highly detailed and realistic visuals. They can produce art, logos, high-quality designs, and unique images.
-
Mistral AI: FMs that are ideal for a wide range of text-based tasks, from summarizing documents to generating and completing code.
On top of that, you can use any of these models as your base, customize them, or import one of your own.
Select the Right Model
Depending on your unique goals, you can choose a base model, select a model to customize, or bring your own model.
Base Models
Base models are designed for general-purpose tasks. You can experiment with base models in Amazon Bedrock’s playgrounds or deploy them in applications where specialized knowledge isn’t necessary. For example, you can use Anthropic’s Claude for writing marketing copy and Stability AI for creating website illustrations. For more information, see Supported foundation models in Amazon Bedrock.
Custom Models
Custom models maintain the foundational knowledge and capabilities of their base models. With customization, you can optimize them to perform better for specific use cases. Customize models using two main approaches: continued pre-training or fine-tuning. Continued pre-training enhances the model’s domain-specific expertise, terminology, and patterns through large amounts of domain-specific data. Fine-tuning teaches the model to perform specific tasks based on a smaller set of labeled examples. For more information, see Customize your model to improve its performance for your use case.
Imported Models
Imported models represent foundation models that you bring into Amazon Bedrock from external sources. These can be open-source models that you’ve modified or proprietary models developed by your organization. Unlike base or custom models, imported models give you complete control over the model architecture, training process, and optimization strategies. For example, consider how a government agency can import a specially developed model for processing documents, a pharmaceutical company can build a proprietary model for drug discovery research, or a financial institution can implement its own risk assessment model.
You can import your own model from an Amazon S3 bucket or Amazon SageMaker AI. After import, use the model in the Amazon Bedrock playgrounds or in your applications. For more information, see Import a customized model into Amazon Bedrock.
Improve Model Performance and Output Quality
In Amazon Bedrock, prompt engineering and inference parameter tuning can affect the output that the model generates.
What’s Prompt Engineering?
Prompt engineering is the practice of designing and refining a model’s input to generate a better output. There are several approaches you can consider based on your use case.
-
Zero-shot prompting means asking the model to perform a task without providing examples.
-
Few-shot prompting includes a small number of examples for the task.
-
Chain-of-thought prompting guides the model to break down complex reasoning into step-by-step thoughts.
-
Retrieval-augmented generation (RAG) extends prompt engineering techniques by retrieving information from an external knowledge base and incorporating it into the response.
For more information on prompt engineering guidelines in Amazon Bedrock, see Prompt engineering concepts.
What’s Inference Parameter Tuning?
Beyond prompt engineering, you can fine-tune model behavior through inference parameters, such as temperature, top P, top K, and the length of the output. The following image displays inference configuration parameters that can help you influence the response.
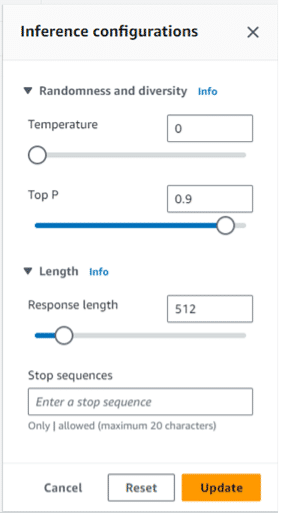
Parameters That Control Randomness and Diversity
-
Temperature (0.0 to 1.0): Temperature controls the randomness in the model’s token selection process. You can adjust the temperature range anywhere between 0.0 and 1.0. A lower temperature tells the model to choose the most probable next token. Thus, the output is always deterministic and consistent. This works best for math, coding, or factual analysis. However, a higher setting of around 0.7 to 1.0 lets the model freely choose from all possible tokens. The outputs of such models are creative and less predictable.
-
Top P (0.0 to 1.0): Top P is another parameter that controls the diversity of responses by limiting the probability of tokens the model considers. If you provide a lower top P number, the model considers only the most likely tokens. The higher top P number offers the model a wider range of tokens. As an example, consider the type of content you want to produce. For financial and technical documentation, keep the value lower. For creative tasks, higher values allow for more diverse responses.
Parameters That Control Length
-
Top K: Top K limits the number of tokens the model chooses from to generate the next token for the output.
-
Response length: Response length controls the maximum number of tokens to generate before stopping.
-
Stop sequences: Stop sequences specifies a character sequence to indicate where the model should stop.
Some FMs might support only select parameters. To check which parameters the model of your choice supports, see Inference request parameters and response fields for foundation models.
Follow Best Practices for Working with FMs
When working with FMs in Amazon Bedrock, it’s essential to follow established best practices to ensure optimal performance, security, and cost-effectiveness. The following list provides key recommendations across areas such as model selection, security, customization, cost management, data handling, and compliance. Use these recommendations as a starting point and adapt them based on your specific use case, industry requirements, and organizational needs.
Model Selection
- Evaluate each model’s strengths and use cases.
- Analyze performance metrics by testing response quality, accuracy, and consistency across different models.
- Review how a model’s supported parameters can help achieve your goals.
- Assess model transparency to understand how model decisions are made.
Security Controls
- Enable encryption in transit using AWS Key Management Service (KMS).
- Implement encryption at rest for all stored prompts, training datasets, and responses.
- Configure AWS Identity and Access Management roles with least-privilege access to Bedrock APIs.
- Keep traffic within the AWS network by using AWS PrivateLink or a gateway VPC endpoint.
- Create security groups to control network access to Bedrock endpoints.
Model Customization
- Design prompting templates for consistent outputs.
- Implement input validation to prevent malicious attacks.
- Create prompt libraries for common use cases.
- Test different prompting techniques.
- Use fine-tuning with labeled examples or continued pre-training to customize your model.
Data Management
- Store data in Amazon S3 or appropriate databases.
- Implement data versioning for prompts, training datasets, and responses.
- Remove sensitive information from Amazon S3 buckets automatically using Amazon Macie.
- Set up backup and retention policies.
- Implement data lineage tracking.
Cost Optimization
- Monitor usage metrics and model performance through Amazon CloudWatch.
- Set up budget alerts in AWS Budgets.
- Modify prompt length to reduce token consumption.
- Use batch processing when appropriate.
- Complete cost analysis and optimization reviews.
Compliance and Governance
- Follow responsible AI principles in model training and usage.
- Enable AWS CloudTrail for API activity logging.
- Use AWS Artifact to store or access compliance reports.
- Monitor your model for bias.
- Set up guardrails to block inappropriate topics.
- Document compliance controls and develop incident response procedures.
Wrap Up
In this unit, you assessed different types of models available in Amazon Bedrock, including base models from leading AI companies, custom models fine-tuned for specific use cases, and imported models from external sources. You also discovered how adjusting model parameters can affect model performance and concluded with comprehensive best practices for working with foundation models. In the next unit, you’ll explore how to bring your own foundation model to Amazon Bedrock, including the requirements, deployment process, and best practices for model hosting and management in Bedrock.